Multimodal LLMs: Architecture, Techniques, and Use Cases
Multimodal Large Language Models (LLMs) integrate diverse data types—text, images, audio, and video—into unified frameworks, enabling advanced applications like image captioning, document analysis, and healthcare solutions.


Introduction to Multimodal LLMs
Multimodal Large Language Models (LLMs) are advanced AI systems capable of processing and generating content across multiple data types, known as modalities, such as text, images, audio, and video. Unlike traditional LLMs, which only handle text-based data, multimodal LLMs are designed to integrate these diverse data types into a unified framework to solve more complex problems. This makes them especially powerful for applications that involve a mix of visual and textual information, such as image captioning or video analysis.
Importance in AI
Multimodal LLMs have become a crucial step in bridging the gap between human-like understanding and machine processing. They allow AI systems to handle more comprehensive and context-rich scenarios by interpreting multiple types of inputs simultaneously. For example, models like GPT-4V or CLIP-based architectures have shown that adding visual understanding to a language model vastly increases its applicability and accuracy in real-world scenarios.
These models are the foundation for many emerging AI tools that can interact more naturally, making them invaluable in industries like healthcare, autonomous driving, and creative content generation.
Evolution of Multimodal Models
The evolution from text-only LLMs to multimodal capabilities is driven by advancements in both hardware and deep learning architectures. Initially, LLMs like GPT-3 could only generate responses based on textual prompts. However, researchers quickly recognized the potential of combining these text models with visual models to create a more holistic AI.
The introduction of cross-attention mechanisms and other architectural innovations, such as the Unified Embedding Decoder and Cross-Modality Attention approaches, has allowed these models to process and generate responses across different modalities effectively. These developments have paved the way for multimodal models like Llama 3.2, which can process both visual and textual inputs to solve complex tasks with human-level context understanding.
Core Architecture of Multimodal LLMs
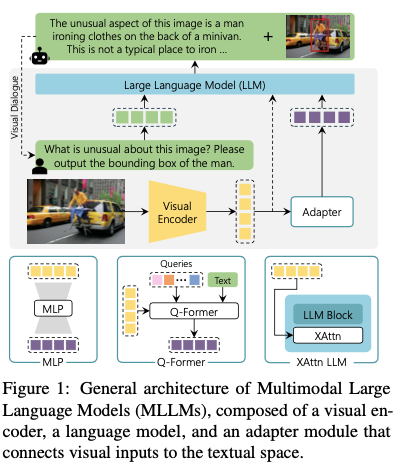
Building Blocks
- Visual Encoders: Visual encoders such as Vision Transformers (ViT), CLIP, and OpenCLIP are responsible for extracting features from image inputs. These encoders are often pretrained and can either remain frozen during model training or undergo further adaptation depending on the specific model architecture.
- Language Model Backbone: The core of a multimodal LLM is typically an existing large language model, such as LLaMA, or other advanced transformer-based models. These models serve as the backbone for handling textual data and integrating multimodal inputs effectively.
- Adapters and Aligners: Components like Q-Former, Linear Projection, and Cross-Attention Modules are used to align non-text modalities to the same embedding space as textual inputs. For example, Q-Former integrates image and text embeddings to form a unified input for downstream tasks.
Architectural Approaches
The diagram below illustrates three main architectural approaches used in multimodal large language models: Cross-Attention, Hybrid, and Decoder-only. Each approach offers distinct methods for integrating visual and textual inputs, providing insights into how different models tackle the challenge of combining multiple data modalities effectively.
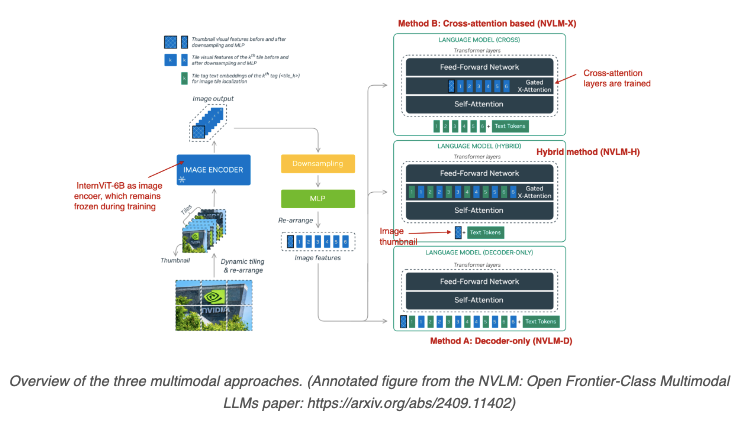
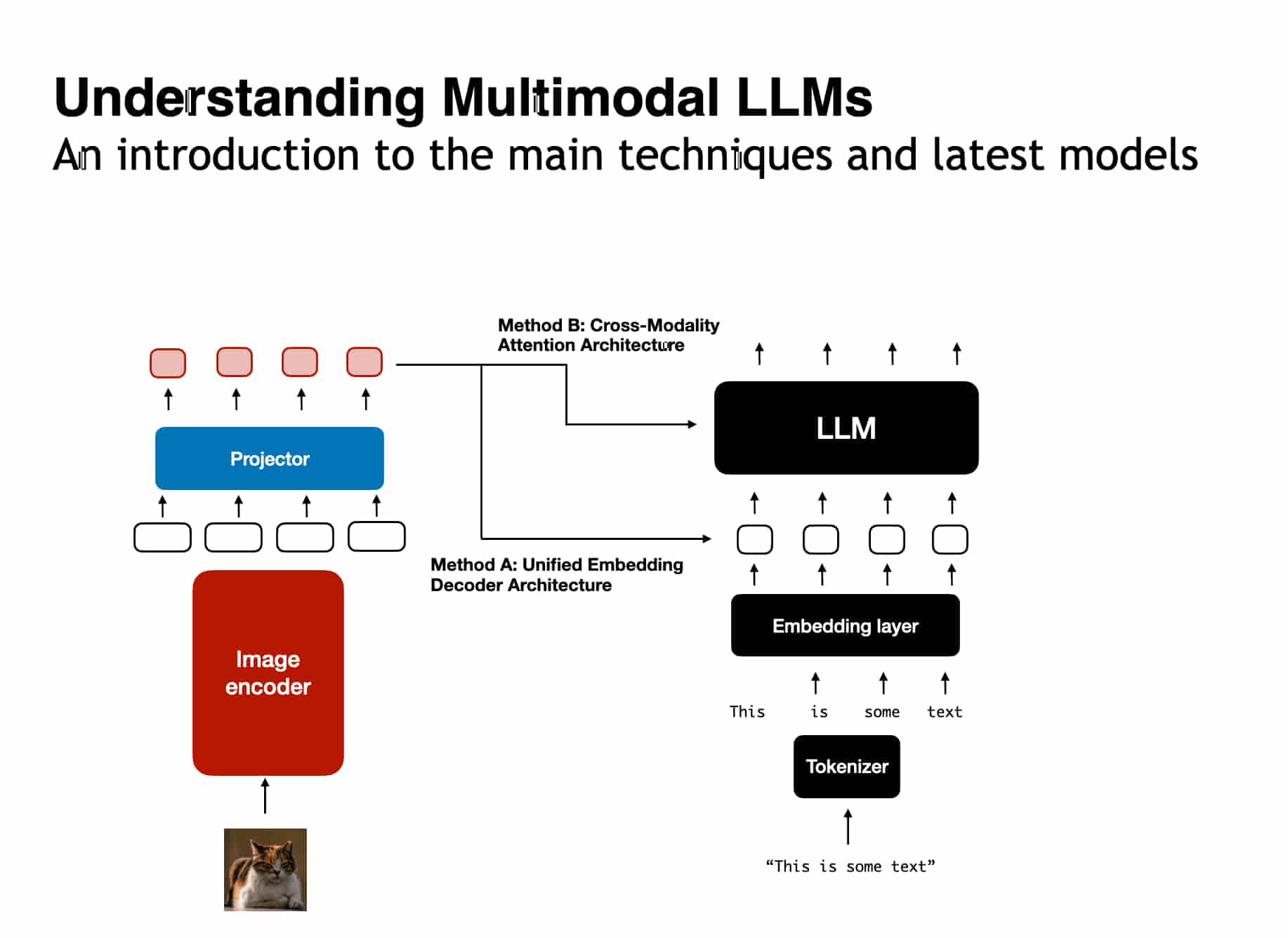
- Unified Embedding Decoder Architecture: This approach uses a single decoder model to handle multiple modalities. Visual inputs are transformed into embedding vectors with the same dimensions as text tokens, allowing them to be concatenated and processed seamlessly by the language model. This is commonly seen in models like Llama 3.2 and GPT-2.
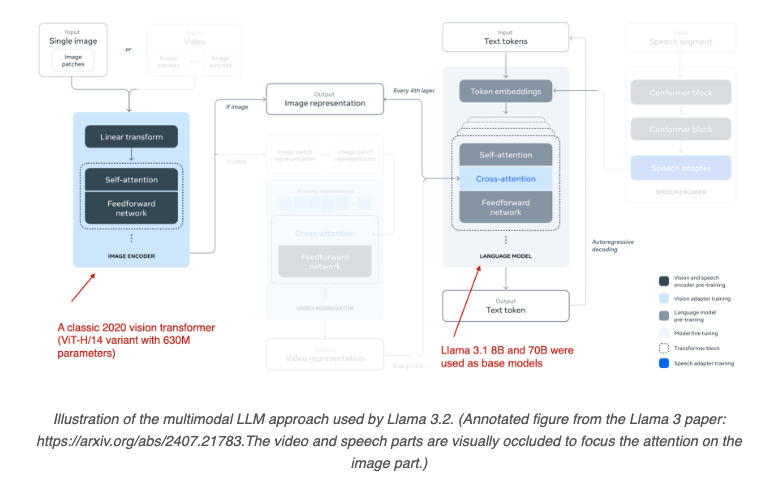
- Cross-Modality Attention Architecture: This architecture employs a cross-attention mechanism to connect visual and text embeddings. The image patches are connected to the text in the multi-head attention layer, allowing for more direct integration between modalities. Cross-attention is inspired by the original Transformer architecture and has proven effective for multimodal tasks.
Training Strategies
- Pretraining and Fine-Tuning: Multimodal LLMs typically undergo a two-stage training process. In the pretraining stage, a pretrained language model is augmented with visual encoders and aligned using adapters. In the fine-tuning phase, the full model is adapted for specific tasks such as image captioning, visual question answering, or image generation.
- Parameter-Efficient Fine-Tuning: Techniques like Low-Rank Adaptation (LoRA) and QLoRA are employed to fine-tune the multimodal LLMs while minimizing computational costs. These methods are particularly useful when updating massive models, allowing for efficient adaptation without retraining the entire model from scratch.
Bash Script for Initial LoRA Training
Below is an example of using Huggingface's AutoTrain to train a model with LoRA on the PremAI platform:
autotrain llm \
--train \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--data-path data/ \
--text-column text \
--lr ${LEARNING_RATE} \
--batch-size ${BATCH_SIZE} \
--epochs ${NUM_EPOCHS} \
--block-size ${BLOCK_SIZE} \
--warmup-ratio ${WARMUP_RATIO} \
--lora-r ${LORA_R} \
--lora-alpha ${LORA_ALPHA} \
--lora-dropout ${LORA_DROPOUT} \
--weight-decay ${WEIGHT_DECAY} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
--quantization ${QUANTIZATION} \
--mixed-precision ${MIXED_PRECISION} \
$( [[ "$PEFT" == "True" ]] && echo "--peft" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN}" )This script uses various parameters, including --lora-r, --lora-alpha, and --lora-dropout to specify LoRA settings, and it helps implement efficient fine-tuning.
Bash Script for Training Using LoRA+
Below is another bash script for training a model using LoRA+:
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python ../..src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--dataset alpaca_gpt4_en,glaive_toolcall \
--dataset_dir ../../data \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir ../../saves/LLaMA2-7B/loraplus/sft \
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \
--preprocessing_num_workers 16 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--warmup_steps 20 \
--save_steps 100 \
--eval_steps 100 \
--evaluation_strategy steps \
--load_best_model_at_end \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--max_samples 3000 \
--val_size 0.1 \
--plot_loss \
--fp16 \
--loraplus_lr_ratio 16.0In this bash script:
- The
--loraplus_lr_ratioparameter is set to16.0, specifying that the learning rate for LoRA+ should be sixteen times that of the base rate, allowing for efficient model adaptation.
Python Implementation for Custom LoRA+ Optimizer
Below is an example of creating a custom optimizer for fine-tuning with LoRA+ using the PremAI platform:
def _create_loraplus_optimizer(
model: "PreTrainedModel",
training_args: "Seq2SeqTrainingArguments",
finetuning_args: "FinetuningArguments",
) -> "torch.optim.Optimizer":
if finetuning_args.finetuning_type != "lora":
raise ValueError("You should use LoRA tuning to activate LoRA+")
loraplus_lr = training_args.learning_rate * finetuning_args.loraPlus_lr_ratio
decay_args = {"weight_decay": training_args.weight_decay}
decay_param_names = _get_decay_parameter_names(model)
param_dict: Dict[str, List["torch.nn.Parameter"]] = {
"lora_a": [],
"lora_b": [],
"lora_b_nodecay": [],
"embedding": [],
}
for name, param in model.named_parameters():
if param.requires_grad:
if "lora_embedding_B" in name:
param_dict["embedding"].append(param)
elif "lora_B" in name or param.ndim == 1:
if name in decay_param_names:
param_dict["lora_b"].append(param)
else:
param_dict["lora_b_nodecay"].append(param)
else:
param_dict["lora_a"].append(param)
optim_class, optim_kwargs = Trainer.get_optimizer_cls_and_kwargs(training_args)
param_groups = [
dict(params=param_dict["lora_a"], **decay_args),
dict(params=param_dict["lora_b"], lr=loraplus_lr, **decay_args),
dict(params=param_dict["lora_b_nodecay"], lr=loraplus_lr),
dict(params=param_dict["embedding"], lr=finetuning_args.lora_embedding_lr),
]
optimizer = optim_class(param_groups, **optim_kwargs)
logger.info("Using LoRA+ optimizer with loraplus lr ratio {:.2f}".format(finetuning_args.loraPlus_lr_ratio))
return optimizerIn this example:
- The
_create_loraplus_optimizerfunction customizes the optimizer to use LoRA+, providing flexibility in how learning rates are applied to different parts of the model (lora_a,lora_b, etc.). - This custom optimizer allows more targeted fine-tuning, enhancing training efficiency.
Key Techniques Enabling Multimodal Learning
- Tokenization for Multiple Modalities: Multimodal LLMs utilize various tokenization strategies for different types of data, aligning the inputs into a unified format. Image inputs, for instance, are often divided into patches and then tokenized using vision transformers, such as ViT or CLIP, which transform visual data into embeddings that can be processed similarly to text tokens. The same approach applies to audio and video modalities, where specific encoders (e.g., HuBERT for audio) are employed to tokenize the respective input.
- Adapters and Connectors: Techniques such as Q-Former and Linear Projection are used to align different modalities into the same embedding space. Q-Former, for example, uses transformers to align image embeddings with language tokens, enabling seamless processing through a single LLM backbone. This component serves as the essential bridge that harmonizes multimodal inputs for downstream processing.
Cross-Modality Attention Mechanisms
- Self-Attention and Cross-Attention: In multimodal models, cross-attention mechanisms are integral for aligning different data types. Cross-attention allows for the direct interaction between textual and visual embeddings, where queries from one modality (e.g., text) are matched with keys and values from another modality (e.g., image). This approach, inspired by the original transformer self-attention model, allows for rich feature extraction and association across multiple data sources.
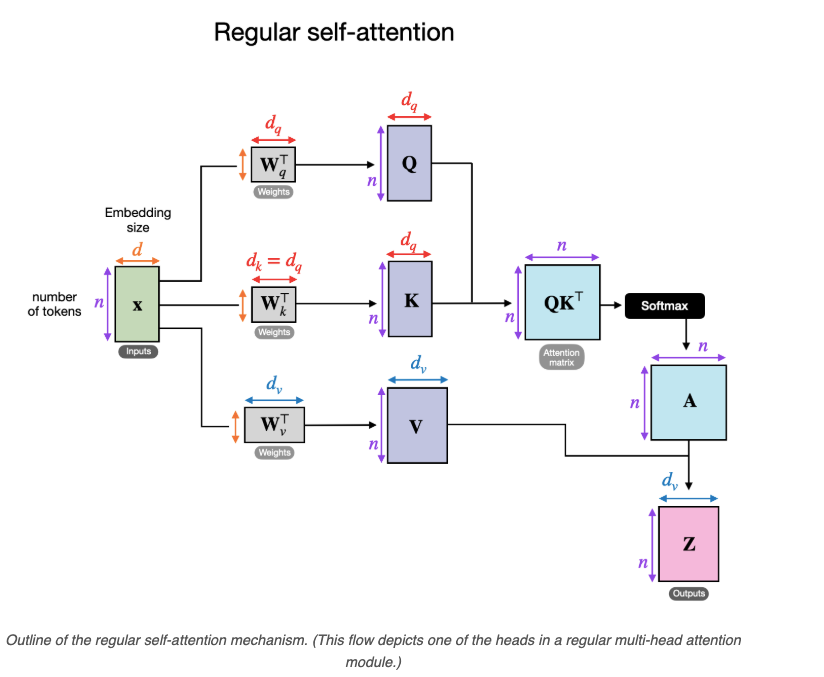
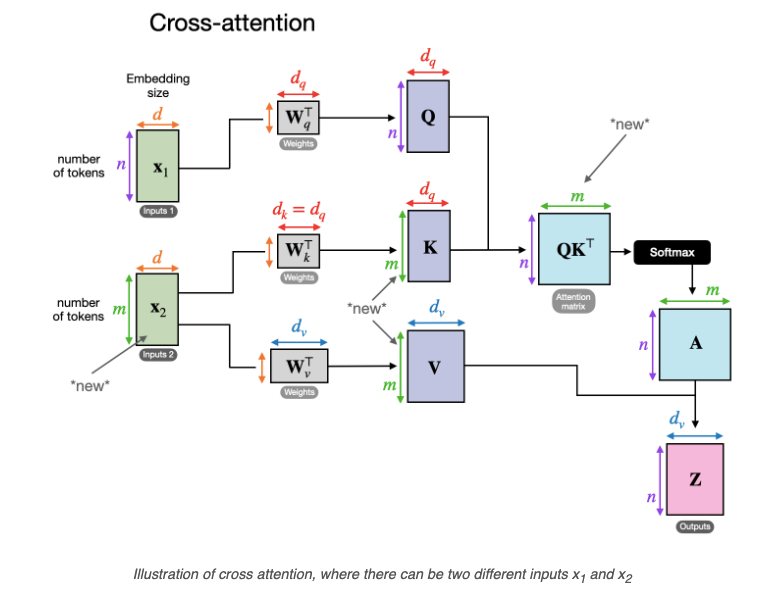
- Layer Integration Strategies: Some models, such as Flamingo and OpenFlamingo, integrate additional cross-attention layers between the pre-trained layers of a transformer to facilitate better integration of visual and textual information. These cross-attention layers are often added selectively to reduce computational overhead while preserving essential features across modalities.
Training Techniques for Multimodal Integration
- Pretraining Modalities: Multimodal LLMs often begin by pretraining separate modalities individually. For instance, visual encoders like CLIP are pretrained on large-scale image-text datasets to learn visual representations that are closely aligned with corresponding text descriptions. Later stages of training focus on aligning these pretrained embeddings with the text embeddings from the language model.
- Parameter-Efficient Fine-Tuning (PEFT): Given the computational costs involved in training large multimodal models, parameter-efficient methods like LoRA (Low-Rank Adaptation) and QLoRA are utilized for effective adaptation to specific use cases .LoRA reduces the number of parameters that need to be fine-tuned, making it feasible to adapt multimodal models to domain-specific tasks without extensive retraining of the entire model.
- Visual Instruction Tuning: To improve the model's response to instructions involving visual inputs, a specialized training phase called visual instruction tuning is employed. This training involves using multimodal datasets where visual prompts are aligned with specific instructions, helping the model improve in tasks like visual question answering and image captioning. Instruction tuning is crucial for aligning the behavior of multimodal models to perform well with human-provided tasks and prompts.
Use Cases of Multimodal LLMs
Multimodal LLMs have a wide range of practical applications across different sectors, leveraging their ability to integrate and understand diverse data types. These models enable more natural interactions and allow for advanced problem-solving capabilities that combine textual, visual, and even auditory information. Below is an overview of some of the most notable use cases:
| Use Case | Description |
|---|---|
| Image Captioning & VQA | Generates descriptions and answers questions about images, valuable for media, education, and accessibility. |
| Document Analysis | Extracts data from documents like PDFs, converting visual elements into structured data formats. |
| Healthcare Applications | Combines medical imaging with patient records to improve diagnostics and personalized healthcare solutions. |
| Retail & E-Commerce | Enhances customer experience through product image analysis, providing detailed descriptions and recommendations. |
| Autonomous Systems & Robotics | Assists in navigation and interaction by integrating visual, auditory, and textual inputs, enhancing adaptability. |
| Content Creation & Digital Art | Facilitates creative workflows by generating or editing images based on textual prompts. |
| Human-AI Collaboration Tools | Supports collaborative projects by integrating visual and textual content, boosting creativity and productivity. |
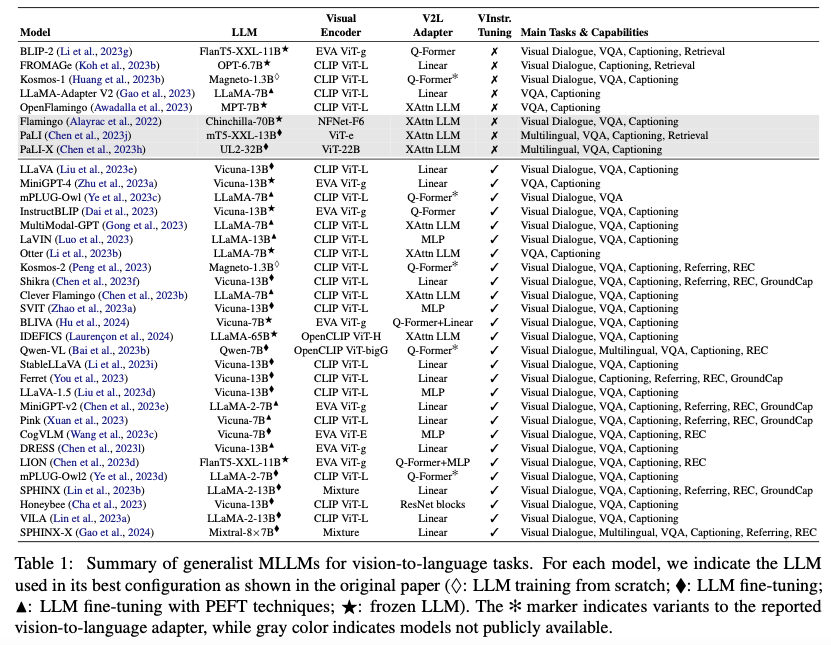
The table below provides an overview of various multimodal large language models (MLLMs), including their architecture components, training methods, and specific capabilities. It highlights the key features and training approaches used in these models, offering insights into how different MLLMs tackle vision-to-language tasks effectively.
Challenges and Future of Multimodal LLMs
Current Challenges
- High Computational Costs: One of the main challenges facing multimodal LLMs is the high computational cost involved in training and deploying these models. The need for extensive hardware resources and energy consumption limits their accessibility, particularly for smaller organizations or researchers without substantial infrastructure.
- Data Alignment Issues: Effective multimodal learning requires large volumes of well-aligned data from multiple modalities. However, collecting and annotating such data is challenging and costly, especially when involving complex domains like healthcare or legal information. Misalignment in data can lead to reduced model performance and inconsistencies in outputs.
- Bias and Fairness: Multimodal LLMs inherit biases present in their training datasets, which can lead to biased or unfair model outputs. This is particularly concerning in applications such as healthcare or law, where biases could lead to serious ethical issues or unfair treatment. Ensuring fairness and addressing biases remain critical research challenges.
- Model Interpretability: As with many deep learning models, understanding and interpreting the decisions made by multimodal LLMs can be difficult. The lack of transparency poses challenges for applications that require accountability, such as medical diagnostics or legal decision-making.
Future Directions

- Improving Computational Efficiency: Advances in parameter-efficient training methods, such as Low-Rank Adaptation (LoRA) and Quantized Low-Rank Adaptation (QLoRA), are expected to play a key role in reducing the computational demands of multimodal LLMs. Developing new techniques that allow for more efficient use of computational resources will help make these models more accessible.
- Better Multimodal Alignment: Future research will likely focus on improving data alignment techniques to enhance the quality and consistency of multimodal learning. Techniques that can automatically align and annotate multimodal datasets could significantly reduce the cost and effort required for data preparation.
- Addressing Bias and Ensuring Fairness: Addressing biases in multimodal LLMs is an ongoing research area. Techniques such as adversarial training, debiasing datasets, and fairness-aware model architectures are being explored to ensure that these models produce fairer and more equitable results.
- Enhanced Interpretability: Improving the interpretability of multimodal LLMs is crucial for their adoption in sensitive domains. Future research may focus on developing methods that provide more insight into the model's decision-making processes, such as attention visualization tools or explanation-generation modules that help users understand why a particular output was generated.
- Domain-Specific Multimodal Models: Creating specialized multimodal models tailored to specific industries or tasks can enhance the performance and applicability of these models. For instance, domain-specific multimodal LLMs in healthcare could integrate medical images, patient records, and literature to provide more accurate diagnostics and personalized treatment recommendations.
Unlocking the Full Potential of Multimodal LLMs
Multimodal LLMs represent a significant advancement in artificial intelligence, providing the capability to process and understand multiple forms of data in a unified framework. By bridging the gap between different data types, these models are pushing the boundaries of what AI can achieve, making them invaluable across various industries—from healthcare and robotics to content creation and retail. However, challenges such as computational costs, data alignment, biases, and interpretability still need to be addressed. Future efforts focusing on computational efficiency, better data alignment, bias mitigation, enhanced interpretability, and domain-specific applications are crucial to fully unlocking the potential of multimodal LLMs and making them more accessible to a wider range of users and use cases.
References: