PremAI Autonomous Fine-tuning System: Technical Architecture Documentation
The Prem AI Autonomous Fine-Tuning System optimizes Small Language Model (SLM) fine-tuning with automated data augmentation, distributed training, and LLM-based evaluation. It minimises manual effort through multi-agent orchestration, hierarchical task classification, and active learning loops.
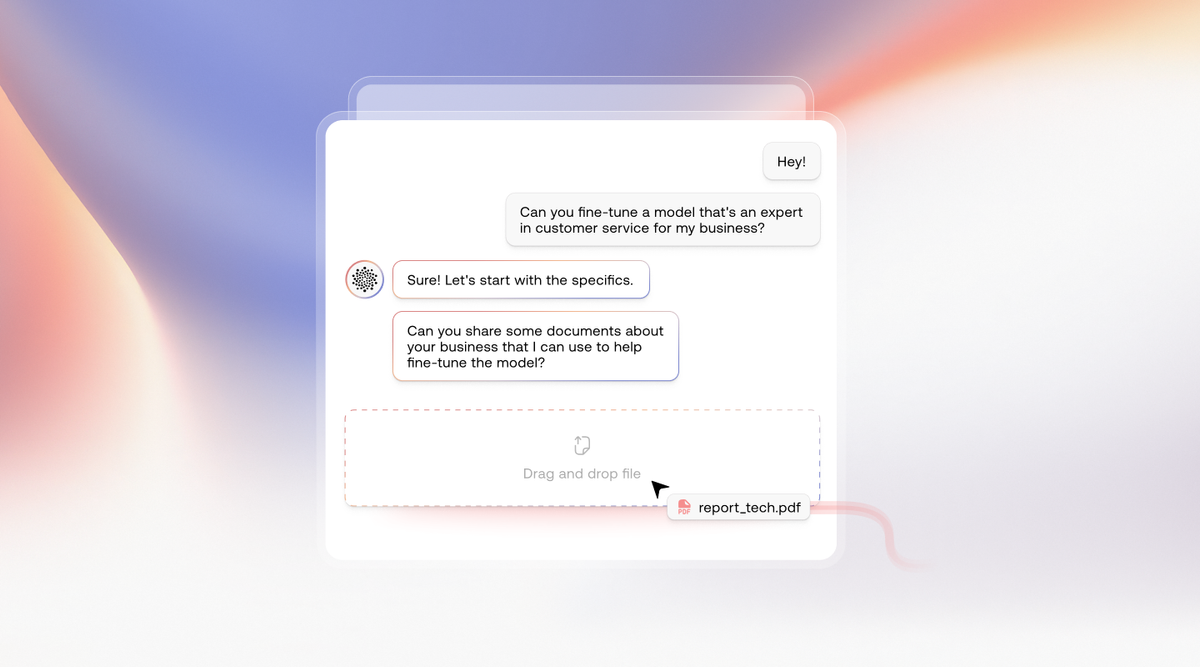
Introduction
The Prem AI Autonomous Fine-tuning System is the productionisation of over 12 months of research effort in the domain of Small Language Model (SLM) finetuning. Unlike traditional fine-tuning approaches that require extensive manually curated datasets and considerable human oversight, our system implements a novel autonomous framework that minimizes human intervention while maximizing model performance through sophisticated data augmentation and distributed training architectures.
System Architecture Overview
The foundational architecture of our system is built upon two interconnected subsystems that work together to deliver optimal fine-tuning results. The first subsystem handles all aspects of data processing, from initial acquisition through augmentation and validation. The second subsystem manages the distributed fine-tuning infrastructure, orchestrating parallel training jobs and implementing comprehensive evaluation protocols.
This bifurcated architecture offers several key advantages over traditional monolithic approaches. By separating data processing from model training, we can independently scale each subsystem based on computational demands and implement specialized optimization strategies for each phase of the fine-tuning process. This separation also enables better fault isolation and more efficient resource utilization across the entire pipeline.
Data Acquisition Framework
Our data acquisition framework implements a multi-modal approach to dataset construction, recognizing that different use cases require different data collection strategies. The system's ability to acquire training data through three distinct channels significantly enhances its flexibility and practical utility.
Interactive Model Analysis Interface
The Prem Playground represents our most sophisticated data collection mechanism. This interface enables users to conduct comparative analyses of multiple models simultaneously, a capability that serves two critical functions. First, it allows for the rapid identification of high-quality model responses through direct comparison. Second, it facilitates the creation of a curated dataset that captures the specific characteristics desired in the fine-tuned model.
The interface implements a novel approach to data annotation where model responses are not simply binary labeled as correct or incorrect, but rather evaluated along multiple dimensions including accuracy, relevance, and stylistic appropriateness. This multi-dimensional annotation scheme backed by best practices provides richer training signals for the fine-tuning process.
Production System Integration
Our production deployment analytics system implements a continuous learning loop that transforms real-world model interactions into valuable training data. This system operates by monitoring live model deployments and implements a user-feedback mechanism to identify high-quality interactions during run time.
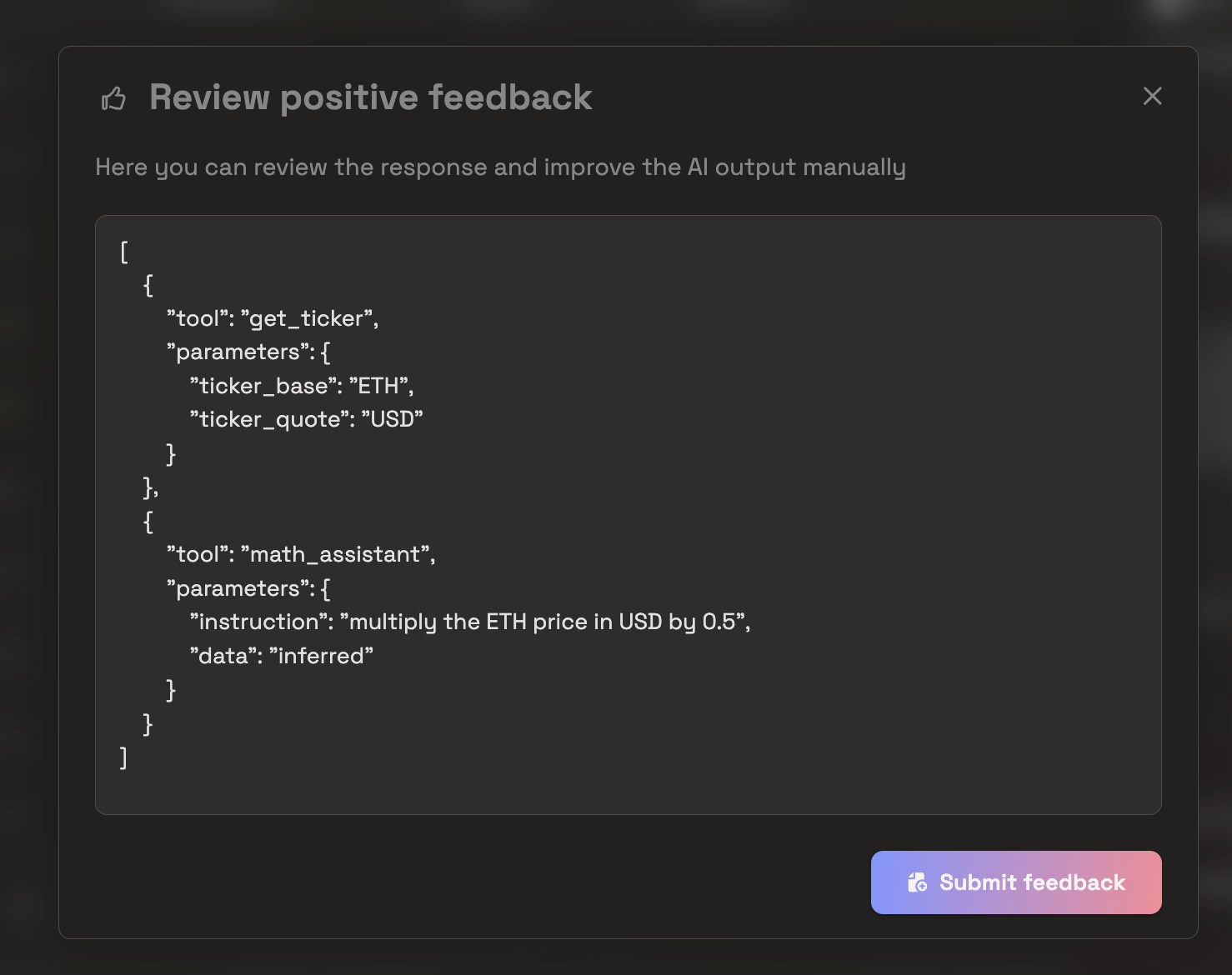
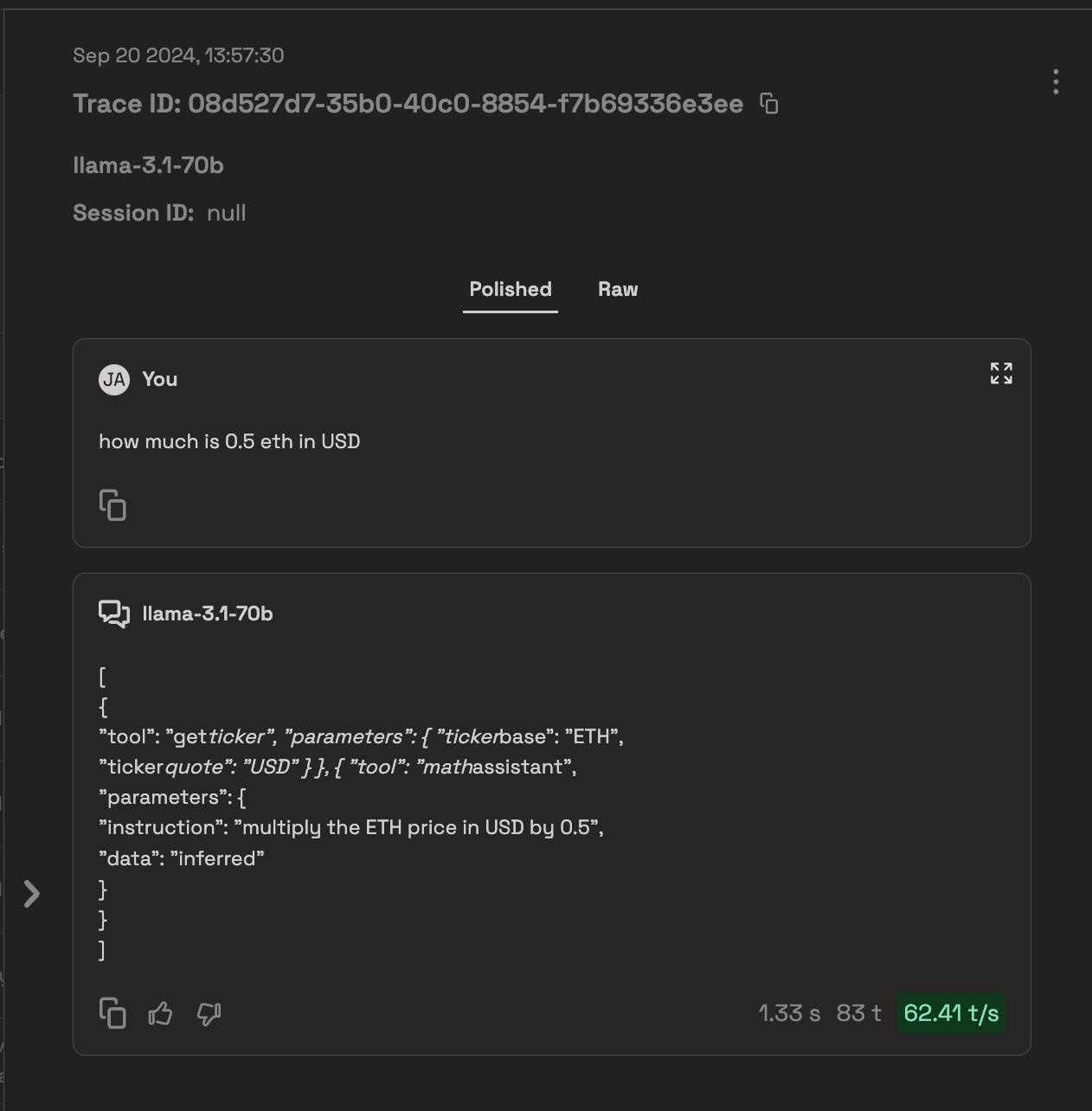
User can also upload CSVs of positively labeled data collected outside of Prem’s Production System.
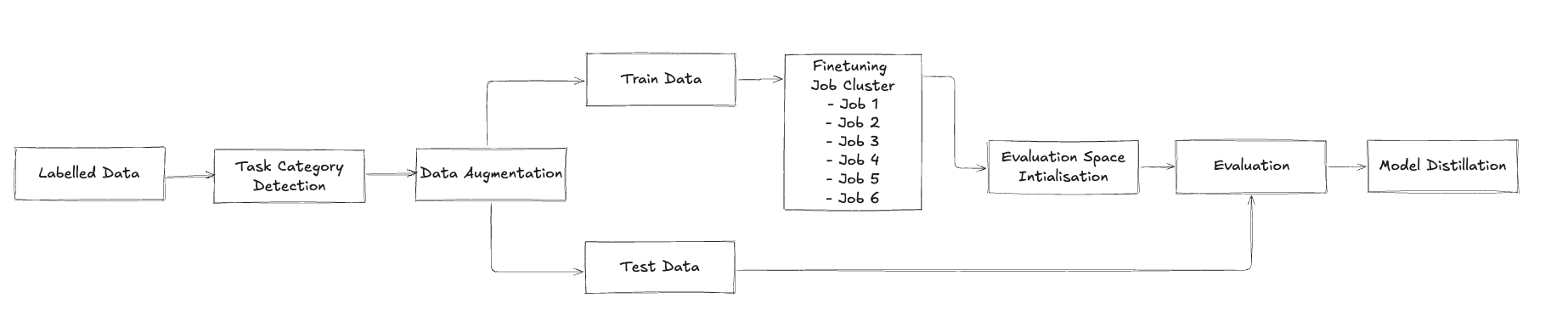
Autonomous Data Augmentation Architecture
Our autonomous data augmentation pipeline represents one of the most innovative aspects of the PremAI Autonomous Fine-tuning System. It orchestrates multiple specialised agents—each responsible for distinct tasks such as topic analysis, data generation, quality filtering, and domain-specific validation—to transform a modest seed dataset (as few as 50 examples) into a large, high-fidelity training corpus (1,000–10,000 or more examples). By systematically coordinating these agents, the pipeline ensures high linguistic and semantic integrity in the synthesized data, even across diverse task categories.
High-Level Pipeline Flow
At a high level, data augmentation proceeds in an iterative loop orchestrated by the Pipeline Controller, the central scheduler that coordinates between specialised agents. These agents typically interact in the following sequence:
- Task Classification & Taxonomy Assignment
- Topic Analysis & Semantic Mapping
- Augmentation Generation
- Agent-Based Verification & Filtering
- Post-Processing & Curated Dataset Assembly
Each step leverages a dedicated set of models and rule-based systems to ensure robust quality control and task alignment.
Task Classification System
The first step in the pipeline is to determine the task type and map it onto a rich, hierarchical taxonomy that captures not only broad categories (e.g., NL2NL vs. NL2C) but also the fine-grained properties that guide data augmentation strategies.
- Hierarchical Task Taxonomy
- Macro-Level Split: NL2NL (natural language transformations) vs. NL2C (e.g., text-to-code tasks)
- Micro-Level Categories: For NL2NL tasks, we identify specific transformation types such as style transfer, knowledge distillation, or numerical questions answering. For NL2C tasks, subcategories (e.g., text-to-SQL, text-to-Python, text-to-HTML) are further classified based on domain constraints, code syntax complexity, and runtime execution considerations.
- Domain-Specific Metadata
- Configuration Flags: For each task, the system sets internal flags that guide subsequent augmentation modules. For instance, text-to-SQL tasks will enable a “sandbox execution” validation step, whereas text-to-Python tasks may invoke additional language model prompts for syntactic correctness checks.
- Difficulty Calibration: A “difficulty index” is computed from seed data attributes (e.g., query complexity in text-to-SQL, advanced syntax usage in text-to-Python, rhetorical complexity for style-transfer tasks). This index helps the augmentation agents generate data points spanning easy, moderate, and challenging difficulty levels.
By thoroughly classifying tasks at both the macro and micro levels, the system can tailor augmentation strategies and validation protocols to each unique scenario.
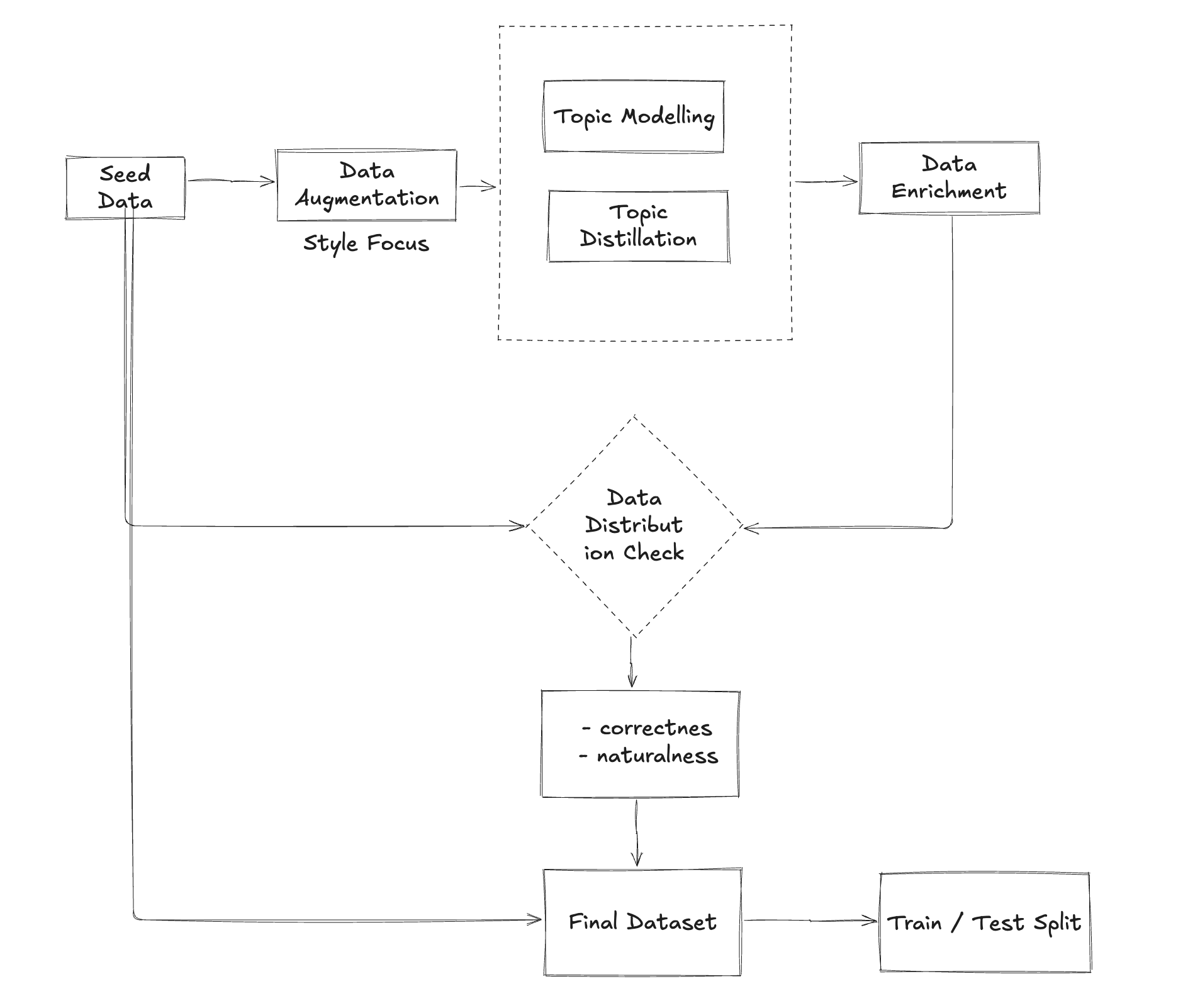
Data Enrichment Pipeline
Once tasks are classified, the pipeline proceeds with a multi-stage enrichment process to systematically expand the seed dataset. This pipeline is implemented as a multi-agent orchestration system wherein various agents handle specialized responsibilities:
- Topic Analysis Engine
- Semantic Scope Extraction: Uses classic NLP techniques (e.g., BERT-based topic modeling, hierarchical clustering) to identify major themes within the seed dataset.
- Hierarchical Clustering: Groups seed examples into clusters of semantically related topics, enabling subsequent agents to generate a more diverse set of examples that preserve contextual coherence.
- Domain Knowledge Integration: Incorporates domain-specific knowledge bases (e.g., schema definitions for text-to-SQL, API references for code-generation tasks) to ensure generated data respects real-world constraints. [OPTIONAL]
- Augmentation Processor
- Controlled Paraphrasing: Applies paraphrase generation models that preserve the core semantics of the seed examples while introducing lexical, syntactic, and stylistic variations (e.g., altering sentence structures, vocabulary choices).
- Context Expansion: Generates new examples by adding or modifying contextual elements—metadata, references, or premises—while ensuring logical consistency with the original seed.
- Scenario Generation: Combines known entities, tasks, and domain rules to create novel scenarios (e.g., new SQL queries based on existing schemas, new prompt contexts for code-generation). [OPTIONAL]
- Difficulty Scaling: Dynamically adjusts the complexity of generated samples using the difficulty index. For instance, in a text-to-SQL setting, simpler queries only join one or two tables, whereas complex queries may involve subqueries, aggregations, or advanced SQL features.
- Validation & Verification Mechanisms
- Multi-Agent Verification: Multiple independent agents (or specialized LLMs) evaluate each augmented sample from different perspectives:
- Semantic Coherence Agent: Checks whether the generated text is contextually consistent with the seed data (e.g., no contradictory statements, no incorrect domain facts).
- Stylistic Consistency Agent: Verifies style guidelines (e.g., formal vs. informal register) if relevant to the task.
- Domain Constraint Validator: For NL2C tasks, code or queries may be tested in sandboxed environments, as recommended by [Ref: https://arxiv.org/html/2409.08239v1]. Failures in execution or syntactic errors lead to automatic rejection or iterative refinement.
- Duplication & Redundancy Filter: Employs hashing or similarity metrics (e.g., universal sentence embeddings, approximate nearest neighbor searches) to detect excessive duplicates. Light duplication is often allowed if it introduces lexical variations, but near-verbatim copies are pruned.
- Multi-Agent Verification: Multiple independent agents (or specialized LLMs) evaluate each augmented sample from different perspectives:
- Quality Scoring & Feedback Loop
- Confidence Scoring: Each augmented sample receives an aggregate confidence score based on the verifying agents’ judgments. Low-scoring samples either get discarded or routed back for partial correction.
- Iterative Refinement: Samples that fail certain checks trigger targeted feedback to the Augmentation Processor, guiding it to generate improved alternatives.
- Curated Dataset Assembly
- Aggregation: Successfully validated samples are batched into the augmented dataset.
- Stratification: The final dataset is stratified by difficulty, topic, and domain to ensure balanced coverage for training.
Metadata Tagging: Each sample is annotated with metadata (e.g., original seed reference, augmentation type, verification status) to support downstream traceability and debugging.
Distributed Fine-tuning Infrastructure
Our distributed fine-tuning infrastructure implements a parallel training architecture that can simultaneously fine-tune multiple model variants while maintaining efficient resource utilization. The system employs advanced orchestration mechanisms to manage training jobs across compute clusters, implementing dynamic resource allocation based on job priority and computational requirements.
Automated Evaluation
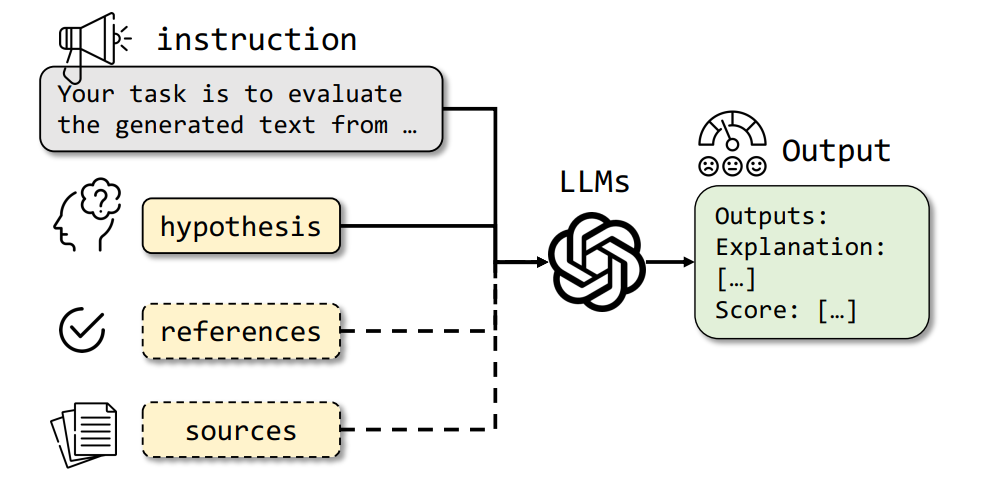
In the current iteration of our Autonomous Fine-tuning System, our entire evaluation pipeline is powered by Large Language Models (LLMs) serving as “judges”. Rather than relying on traditional statistical metrics (accuracy, BLEU, ROUGE, etc.) or human reviews, we harness advanced LLMs that have been trained—often with Reinforcement Learning from Human Feedback (RLHF)—to deliver judgments that closely align with human preferences. This LLM-based approach enables scalable, near-human-level evaluations across a wide range of tasks without the overhead typically associated with human labeling.
LLM-Centric Evaluation Pipeline
All candidate model outputs—whether from interactive user queries or batch test sets—are forwarded to one or more LLM “judges.” These judges produce qualitative and quantitative assessments of the outputs based on pre-configured evaluation criteria. The high-level flow is as follows:
- Candidate Model Generation
- A candidate model receives a prompt (or test input) and generates a response.
- This output is then fed into the evaluation pipeline.
- LLM Judge Prompt Construction
- Each evaluation query is accompanied by a specialized prompt template that instructs the LLM judge on what factors to consider (e.g., correctness, coherence, style, or domain constraints).
- Prompts often contain guidance like:
- “Rate this response on a scale from 1 to 10 in terms of correctness and helpfulness.”
- “Explain any logical gaps or factual inaccuracies in the response.”
- “Check the code block for syntax errors and see if it meets the user’s requirements.”
- LLM Judgment & Scoring
- The judge LLM processes the prompt and the candidate output, then provides a single or multi-dimensional score (e.g., correctness = 8/10, style = 7/10) along with rationales or explanations.
- These rationales allow the system to trace the judge’s reasoning, offering insights into potential error modes or edge cases.
- Aggregate Score Computation
- If multiple judges are used in parallel (e.g., ensembling or cross-checking approaches), their scores are combined using a weighted scheme.
- A single composite score (or set of scores) is then logged in the model leaderboard, making it easy to compare multiple candidate models.
- Continuous Iteration
- The pipeline repeats this process for a broad range of inputs—covering everything from trivial cases to complex, adversarial queries.
- Over time, as new data or new candidate models become available, the judge LLM-based scoring evolves to reflect model improvements or regressions.
Prompt Engineering for LLM Judges
Because LLM-based evaluations can be prompt-sensitive, we employ rigorous prompt engineering strategies:
- Chain-of-Thought vs. Single-Step Reasoning
- For complex tasks (e.g., multi-step reasoning, math-heavy queries, code compilation), the LLM judge might be prompted to explicitly explain its reasoning step by step before issuing a final verdict.
- For simple tasks or high-volume evaluations, a single-step prompt can suffice to reduce latency and computational costs.
- Domain-Specific Instructions
- Each domain—NL2SQL, text summarization, style transfer, code generation—has custom prompts that guide the LLM judge to check the relevant constraints (e.g., correctness of SQL queries, stylistic fidelity in re-writes, etc.).
- We also feed contextual domain information (e.g., a database schema) into the prompt so the judge can verify domain-specific correctness.
- Self-Consistency & Double-Check
- In some configurations, the LLM judge is asked to re-check or self-evaluate its initial scoring, ensuring higher reliability.
- Additionally, a second pass from a distinct LLM or a re-prompt to the same LLM can identify overlooked details or contradictory reasoning.
Dimensions of LLM-Based Judgments
Though we do not use standard automated metrics in the current pipeline, the LLM judge often emulates them by focusing on specific aspects:
- Correctness & Factuality
- For text-to-SQL or code-related tasks, the judge checks if the response logically or syntactically fits the user’s prompt or environment constraints.
- For knowledge-intensive tasks, the judge looks for factual errors or hallucinations.
- Coherence & Fluency
- The judge assesses whether the output is coherent, well-structured, and maintains a consistent style or tense.
- Adherence to Instructions
- Many user tasks are preceded by explicit instructions about style, format, or disclaimers. The judge checks if the model faithfully follows these instructions.
- Conciseness & Relevance
- The judge scores how directly and efficiently the model addresses the user’s query. For instance, verbose or tangential answers may be penalized.
- Safe & Non-Toxic Content
The judge is prompted to identify any offensive, biased, or harmful language in the output, aligning with ethical usage guidelines.
The infrastructure includes model selection mechanisms that automatically identify the best-performing model variants based on a weighted combination of evaluation metrics. This selection process considers both quantitative performance metrics and practical deployment constraints, ensuring that selected models meet both technical and operational requirements.
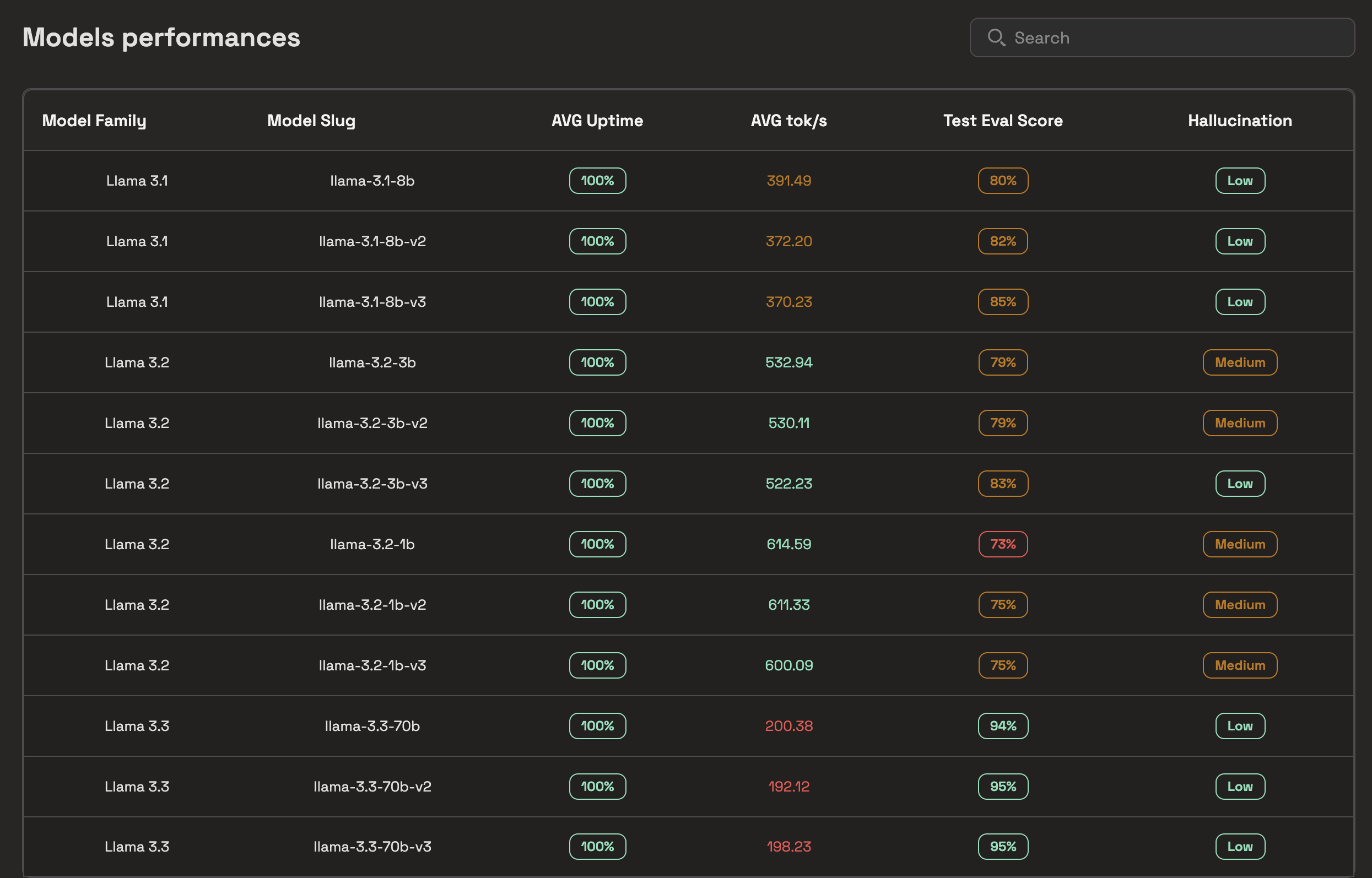
Active Learning Loop
Now ideally user can select the top models, and then use these models to empirically test / red-team in Prem Platform's playground which in turn populates more examples, which can be further used to fine-tune the best models (continual learning).
Future Directions
The system's modular architecture provides numerous opportunities for future enhancement and expansion. Potential areas for development include:
- Implementation of more sophisticated data augmentation strategies using emerging language model architectures
- Enhanced cross-model knowledge transfer mechanisms
- Advanced resource optimization algorithms for distributed training
- Expanded evaluation frameworks incorporating novel metrics and benchmarks
These developments will further enhance the system's capabilities while maintaining its core principles of autonomy, efficiency, and reliability.
Our Edge
Our edge lies in a few core components
- Novel Agentic Synthetic data generation methods which aligns with the topics around seed dataset scaled across multiple tasks and use cases.
- Distributed fine-tuning infrastructure that fine-tunes several models and evaluates them with generalized and task specific evaluation suite (both on cloud and on premise hardware)
- A closed loop workflow of continual learning, where user can do red teaming and empirical evaluation which would again gather more seed data to carry out next iterations of fine-tuning.
Autonomous Fine tuning success stories
Prem-1B-SQL
Prem-1B-SQL is one of our most successful and recent outcomes of Prem’s Autonomous fine-tuning workflow. Text to SQL or Natural Language to SQL plays a very important role in AI copilots for data analysis. Hence, of the most valuable and exciting use cases of AI is Natural Language to SQL (NL2SQL), which enables autonomous AI-driven data analysis without the steep learning curve.
However we saw that, current best Text to SQL models are either closed source or are very big (parameter size ≥ 70B). To get better results in text to SQL like tasks, it is often adviced to give table rows as examples to the model’s context, however using closed source models could lead to a breach of data privacy, because data might contain lots of PIIs. Hence, it was clear, that there exists a need of small language models, which could show on par performance like the closed source or larger open source models.
We used Prem’s Autonomous fine-tuning workflow to fully fine-tune DeepSeek coder 1.3B model to overal several stages using already existing datasets and we synthetically generated around 50K samples which accelerated the performance by a significant margine.
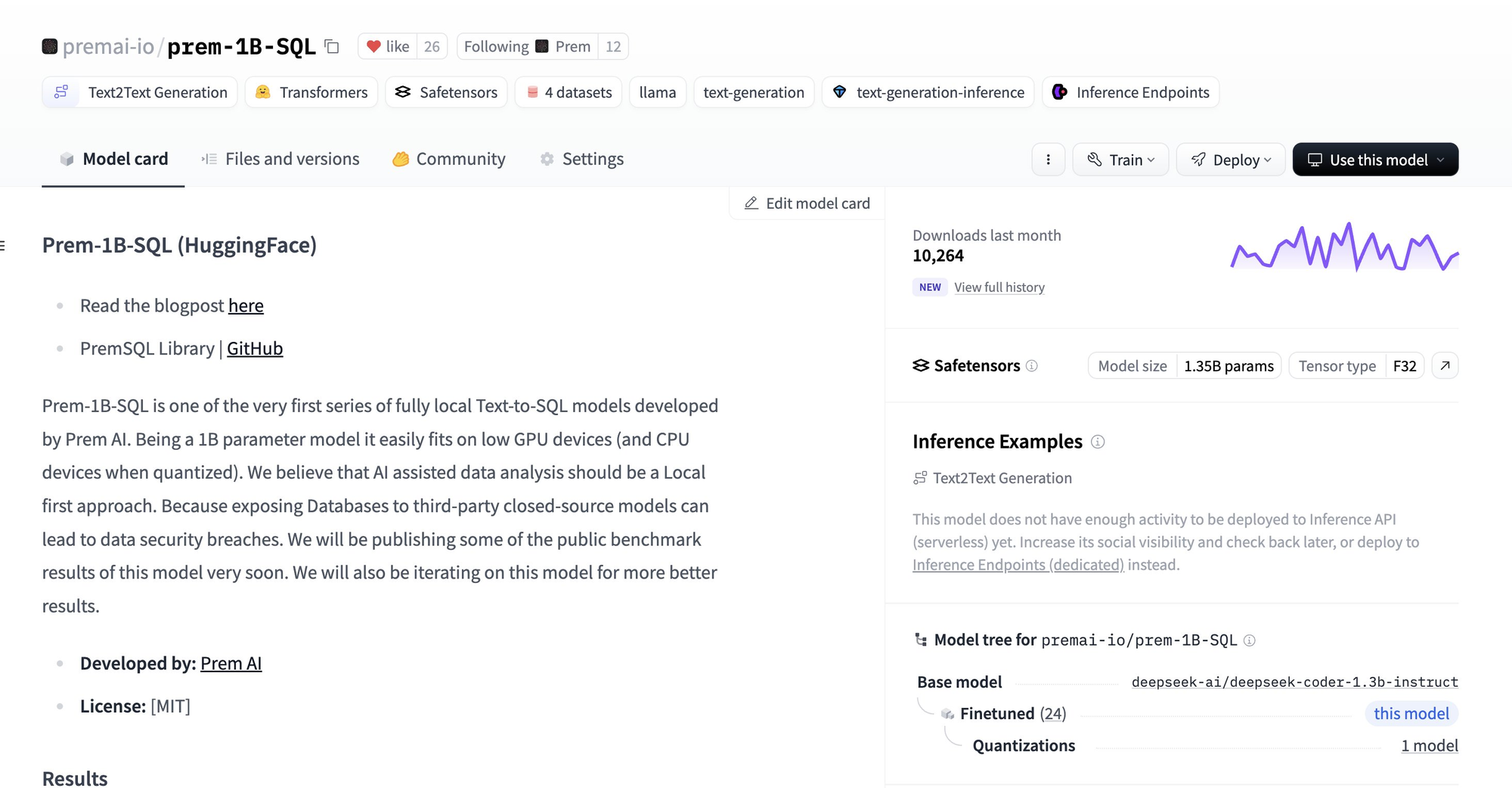
We open-sourced Prem-1B-SQL on Hugging Face, and the community loved it! As shown in the image, we surpassed 10K+ monthly downloads. We also open-sourced PremSQL, a library that helps developers work on Text-to-SQL tasks and enables users to perform RAG on databases with just a few lines of code. So far, we've reached almost 300 stars on GitHub and 8K+ library downloads. Learn more about PremSQL and Prem-1B-SQL in the blog below.

Synthetic Data generation pipeline for Text to SQL
Text to SQL falls under the category of Natural Language to Code (NL2C). Before understanding the data generation process, let’s understand the contents of the data specific to Text to SQL. Datasets for Text to SQL consists of a database schema (which will contain all the table information), the user’s question and additional business logics (for example the meaning of some columns or expansion of short hand column names etc). The ground truth consists of the SQL query which would have retrieved correct dataframe as output.
Using our data augmentation agents, we take each positive samples, we described the difficulty level. We extrapolated each sample by 10-20 datapoints. We already knew the schema and the SQL query of the real positive sample. Our synthetic data generation agents then constructs similar user queries which revolves around the output dataframe (which we would get from the real positive SQL query).
During filtering we take out some samples, which are duplicated however we also keep duplicated samples, where the outcomes are duplicate but the question constructs are different. This gave us an additional 50,000 + samples. We used this data to fine-tune a series of Open Source Small Language Models.
Running parallel fine-tuning job to train models for Text to SQL
We fine-tuned models like LLama 3.2 3B, IBM Granite 3B / 1B, Gemma 2B, DeepSeek coder 1.3B. Out of these, we saw that after some batch runs, DeepSeek coder gave us better results than others. This resulted to continually fine-tune DeepSeek coder for another round of fine-tuning with additional 8k-10K samples (real and synthetically generated).
For evaluation, we used specialized evaluation pipelines for Text to SQL, which measured the execution accuracy and Valid Efficiency Score of the models. With rising validation score, gave us better metrics and made us confident to make a submission of our model to BirdBench (powered by Qwen Team) private test set Text to SQL benchmark. We received a score of 51.54%, being the first 1B parameter model to achieve this score compared to other bigger models. Here is more details on the comparision with other models. Table 1 and figure 1, shows the performance comparision of Prem-1B-SQL with other closed and open source LLMs.
| Model | # Params (in Billion) | BirdBench Test Scores |
|---|---|---|
| AskData + GPT-4o (current winner) | NA | 72.39 |
| DeepSeek coder 236B | 236 | 56.68 |
| GPT-4 (2023) | NA | 54.89 |
| PremSQL 1B (ours) | 1 | 51.4 |
| Qwen 2.5 7B Instruct | 7 | 51.1 |
| Claude 2 Base (2023) | NA | 49.02 |
Table 1: Performance Comparision of Prem-1B-SQL with other open and Closed Source Models on BirdBench private benchmarks.
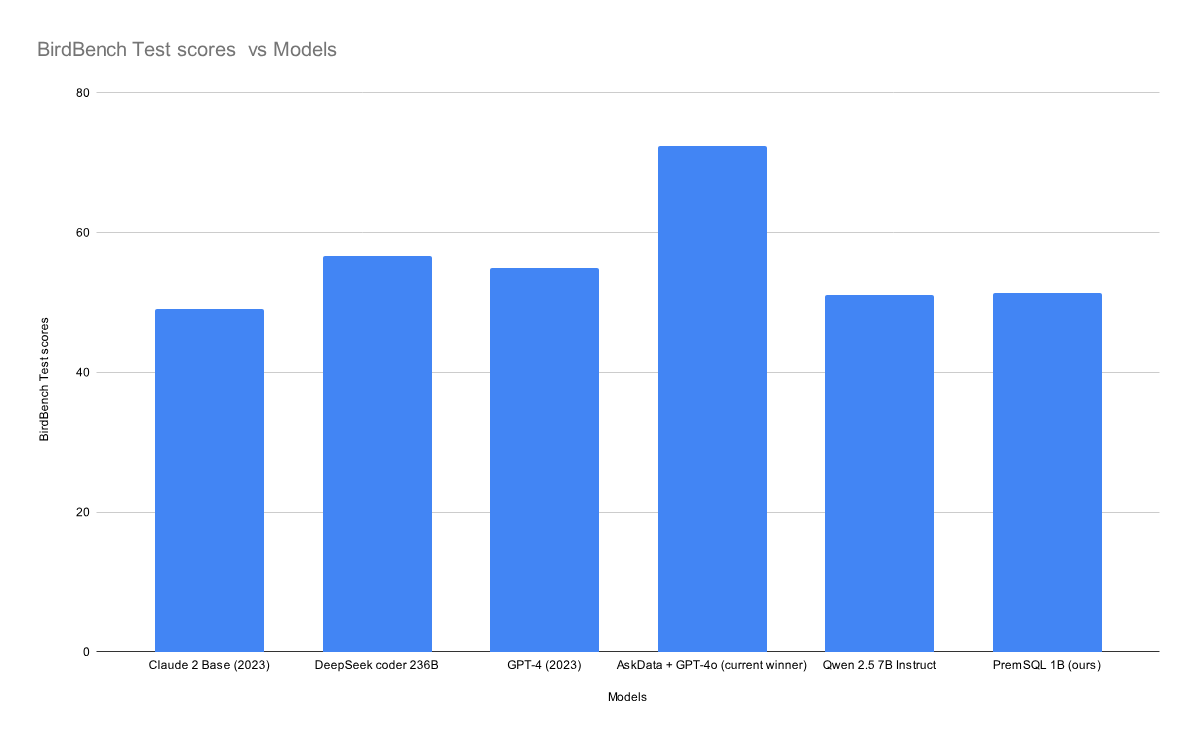
BirdBench is a Private benchmark for Text2SQL tasks, powered by the Qwen from Alibaba Team. The test questions maintains a fair share of varying level of difficulties. Table 2 shows the scores on those varying level of difficulties:
| Difficulty | Count | EX | Soft F1 |
|---|---|---|---|
| Simple | 949 | 60.70 | 61.48 |
| Moderate | 555 | 47.39 | 49.06 |
| Challenging | 285 | 29.12 | 31.83 |
| Total | 1789 | 51.54 | 52.90 |
Table 2: BirdBench Private benchmark test scores on varying level of difficulties.
Prem-1B-SQL also got a huge surge with whopping 11K + model downloads (as of November 2024) and lots of love from the community. We also open sourced some version of the code (mode training / datasets / evaluation pipelines) and got 250+ stars on GitHub. You can check out more about the model in our official release blog.
How do you use Prem’s Autonomous Finetuning Agents for Novel Models?
Using Prem’s Autonomous Fine-Tuning Agents can be a straightforward process when approached methodically. Below are some recommended best practices and tips to help you extract the maximum value from the platform:
- Start Small, Iterate Frequently
- Begin with ~50 well-curated examples for your specific use case. Even a small dataset can serve as a strong foundation when combined with the system’s autonomous data augmentation.
- Conduct short training runs to quickly evaluate if you’re on the right track. Shorter, frequent training cycles let you detect issues early—such as mislabeled data or unsuitable hyperparameters—without expending excessive resources.
- Use the Prem Playground for Rapid Feedback
- Leverage the interactive comparison feature in the Prem Playground to quickly gauge which model variant is performing well on your task.
- Perform red-teaming tests by providing diverse, challenging prompts. This not only uncovers vulnerabilities but also creates high-value data for subsequent fine-tuning stages.
- Emphasize Quality in Data Collection
- Automated data harvesting from production systems is powerful, but ensure you incorporate clear filtering and quality checks. Use domain-specific rules and engagement metrics to keep your training data relevant and noise-free.
- Multi-dimensional annotations (accuracy, relevance, style, etc.) can provide richer signals for model training, resulting in more robust outcomes.
- Make the Most of Autonomous Data Augmentation
- Rely on the platform’s multi-agent orchestration to expand your dataset systematically without compromising on semantic consistency.
- Configure domain constraints carefully to avoid generating irrelevant or contradictory samples. For instance, if you’re focusing on code generation, ensure that your sandboxed environment and validation criteria are well-defined before augmentation begins.
- Choose the Right Model Family & Resources
- Select a model family that aligns with your task domain (NL2NL, NL2C, or specialized models like Text to SQL). Each family has different baseline capabilities and constraints.
- Budget resources based on your expected training duration and hardware availability. The system’s distributed training and dynamic resource allocation work best when you provide realistic constraints upfront.
- Continuously Evaluate & Prune
- Run parallel trainings on different model candidates and let the system’s leaderboard identify top performers. This multi-model strategy helps surface unexpected winners (smaller models may outperform bigger ones for certain tasks).
- Prune underperforming models early to save computational resources. Focus on refining promising candidates with additional synthetic data or domain-specific fine-tuning.
- Close the Loop with Active Learning
- Continually gather new examples from both user feedback and system logs. The more “real-world” data you incorporate, the more resilient your models become.
- Use feedback modification tools in the Prem Platform to annotate or correct model responses. These corrected examples directly fuel the next iteration of fine-tuning.
- Integrate via API for Automation
- Automate your data pipelines by calling Prem’s fine-tuning APIs, enabling you to trigger new training jobs as soon as fresh data becomes available.
- Implement continuous integration (CI) checks that automatically spin up small-scale training runs for any new dataset changes, ensuring quality remains consistent over time.
All this can be done via an API / Prem’s Platform.
Prem Documentation:
