SLM Journey Unveiled
Prem’s "SLM Journey Unveiled" details training a 1B parameter Small Language Model with 8K context length. It covers dataset challenges, Distributed Data Parallelism (DDP) with Ray, and optimization techniques for data partitioning and gradient synchronization.

In recent months, the landscape of language models has been enriched by the emergence of several small language models (e.g. TinyLlama, Phi2, Gemma, and StableLM2) prompting investigations into their capabilities and potential applications. Key questions have arisen regarding the emergent capabilities of these compact models, their practical utility, and the necessity of large language models with billions of parameters for tasks like summarization.
We aim to explore whether SLMs can offer comparable performance to LLMs while maintaining a smaller footprint, faster execution, and improved manageability. We seek to harness the potential of SLMs to revolutionize language processing solutions, making them more accessible and efficient.
In this pursuit, our hypothesis posits that fine-tuned SLMs, when tailored to specific tasks, can achieve performance levels similar to those of fine-tuned LLMs on the same task-specific datasets.
In this blog post, we establish the groundwork for training our SLM, addressing encountered challenges and detailing pivotal decisions made along the way.
🚀 Conquering Trillion-Token Datasets
In the realm of training SLMs/LLMs, grappling with massive datasets spanning trillions of tokens, such as SlimPajama-627B, presents a formidable challenge. Relying solely on a single device proves inadequate for handling such scale. Enter distributed training—an indispensable solution that not only expedites but also renders feasible this daunting task.
Before we delve into Distributed Data Parallelism (DDP), it's crucial to recognize that our current objective is to train a model with 1 billion parameters and an 8K context length. This specific configuration currently enables us to comfortably fit the model onto a single GPU, considering the memory usage. In the event of a potential future expansion into larger context sizes or increased model complexity, the transition to Fully Sharded Data Parallelism (FSDP) becomes crucial. This shift is necessary to guarantee efficient training across multiple devices, particularly considering the heightened memory demands associated with scaling up.
Although a single GPU can host our SLM, the bottleneck predominantly resides in processing power. DDP effectively tackles this challenge by leveraging the collective computational prowess of multiple devices. This parallel processing methodology substantially amplifies training speed and efficiency, thereby streamlining the management of larger datasets and attaining higher iterations per second (it/s).
When implementing DDP effectively, attention must be paid to two critical considerations:
- Meticulous partitioning of data across devices: essential for preventing redundant processing of the same data points.
- Seamless synchronization of gradients: vital to ensure uniformity in model updates across all device copies.
Furthermore, addressing latency in communication, both within GPUs and across nodes, is imperative, as it significantly impacts the efficiency of the training process.

🌐 Exploring Ray and Distributed Computing
Before delving into the challenges we faced during SLM training with DDP, let's first develop a concise understanding of Ray and its significant role in distributed computing. Among the multitude of tools at our disposal, Ray emerges as a standout option. In our preceding section, we delved into the intricacies of distributed training and DDP, yet Ray's core strength lies in adeptly handling tasks and data parallelism across distributed environments. Ray offers a comprehensive suite of libraries, including Ray Data, Ray Train, Ray Tune, Ray Serve and RL, each encompassing different facets of distributed computing.
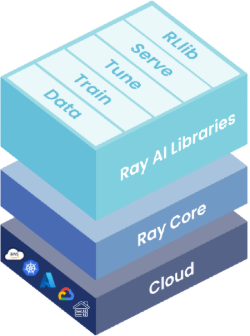
But what truly distinguishes Ray is its robust fault tolerance mechanisms, ensuring seamless operation even in the event of node failures. Here's a breakdown of Ray's key features:
- Distributed Task Execution: Ray enables parallel execution of tasks across multiple nodes, optimizing resource utilization for enhanced performance.
- Actor Model: Leveraging lightweight and isolated entities called actors, Ray facilitates concurrent and distributed computation, enhancing efficiency and scalability.
- Fault Tolerance: With mechanisms like task and actor state checkpointing, Ray ensures reliable performance, maintaining operational stability in the face of failures.
- Scalability: From single-node setups to expansive clusters, Ray seamlessly scales to accommodate varying computational demands, dynamically adjusting to optimize efficiency.
- Python API and ML Integration: Ray offers a user-friendly Python API and seamlessly integrates with popular machine learning libraries, facilitating efficient distributed training and inference of ML models.
🏋️ Empowering DDP Training
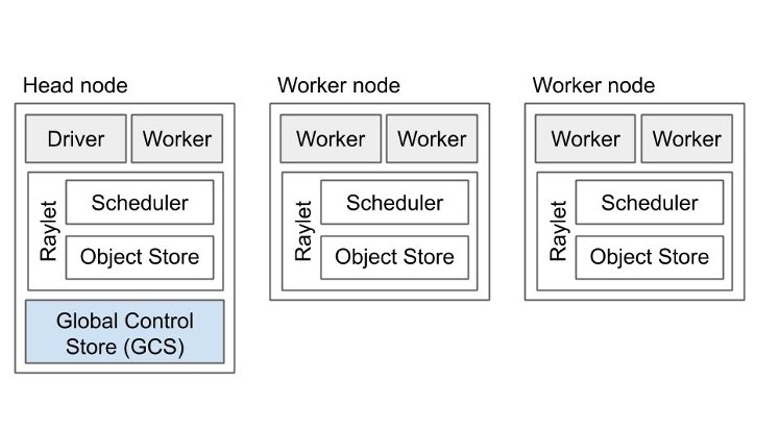
Up to this point, we've recognized the necessity of DDP for efficiently training our SLM, and we've acknowledged Ray's role as a facilitator of distributed computing. Now, we can integrate both by introducing Ray clusters and their effectiveness for distributed training. This also enables us to grasp the challenges inherent in distributed training and how Ray provides an abstraction layer to address them. Within Ray, distributed training operates within a Ray Cluster, where:
- A singular head node manages cluster operations such as autoscaling and Ray driver processes, while also functioning as a worker node.
- Multiple worker nodes execute user code in Ray tasks and actors, managing distributed scheduling and memory allocation.
When setting up a cluster for distributed training, organizations typically choose from various deployment options based on their specific needs. Among these options are Kuberay and Ray On-Premises Deployment. Kuberay seamlessly integrates with Kubernetes, a leading container orchestration platform, merging Ray's distributed computing framework with containerized environments. This integration provides a scalable and adaptable solution for deploying distributed applications. Alternatively, organizations can opt to manually create a Ray cluster by initiating the Ray head process on a designated node and attaching other worker nodes to it, thereby establishing a bare Ray cluster. This approach offers complete control over the environment for job submissions, enhancing flexibility.
Here, we encounter our first challenge and pivotal decision point on the path toward establishing the foundation for training our SLM. Between Kuberay and the manual setup of Ray On-Premise, we've chosen the latter due to specific Python environment requirements. Our reliance on flash-attention for memory optimization and training performance enhancement necessitated a customized installation process beyond the scope of a simple pip install command. Although Ray allows for the specification of Python dependencies through conventional means like a list of packages or a requirements.txt file, the setup complexities of flash-attention warranted a more tailored approach. While this customization was manageable for our cluster's size (refer to cluster setup), scaling to larger clusters could introduce additional intricacies, as each node would require manual configuration.
Stepping beyond the initial hurdles of configuring our on-premise Ray cluster, let's highlight Ray's flexibility for distributed training. Ray's seamless integration with leading training frameworks like Hugging Face, PyTorch, and PyTorch Lightning underscores its suitability for diverse distributed training scenarios. This versatility enables effortless transitions between different strategies, such as shifting from DDP to FSDP or DeepSpeed, amplifying the flexibility and scalability of distributed training setups.
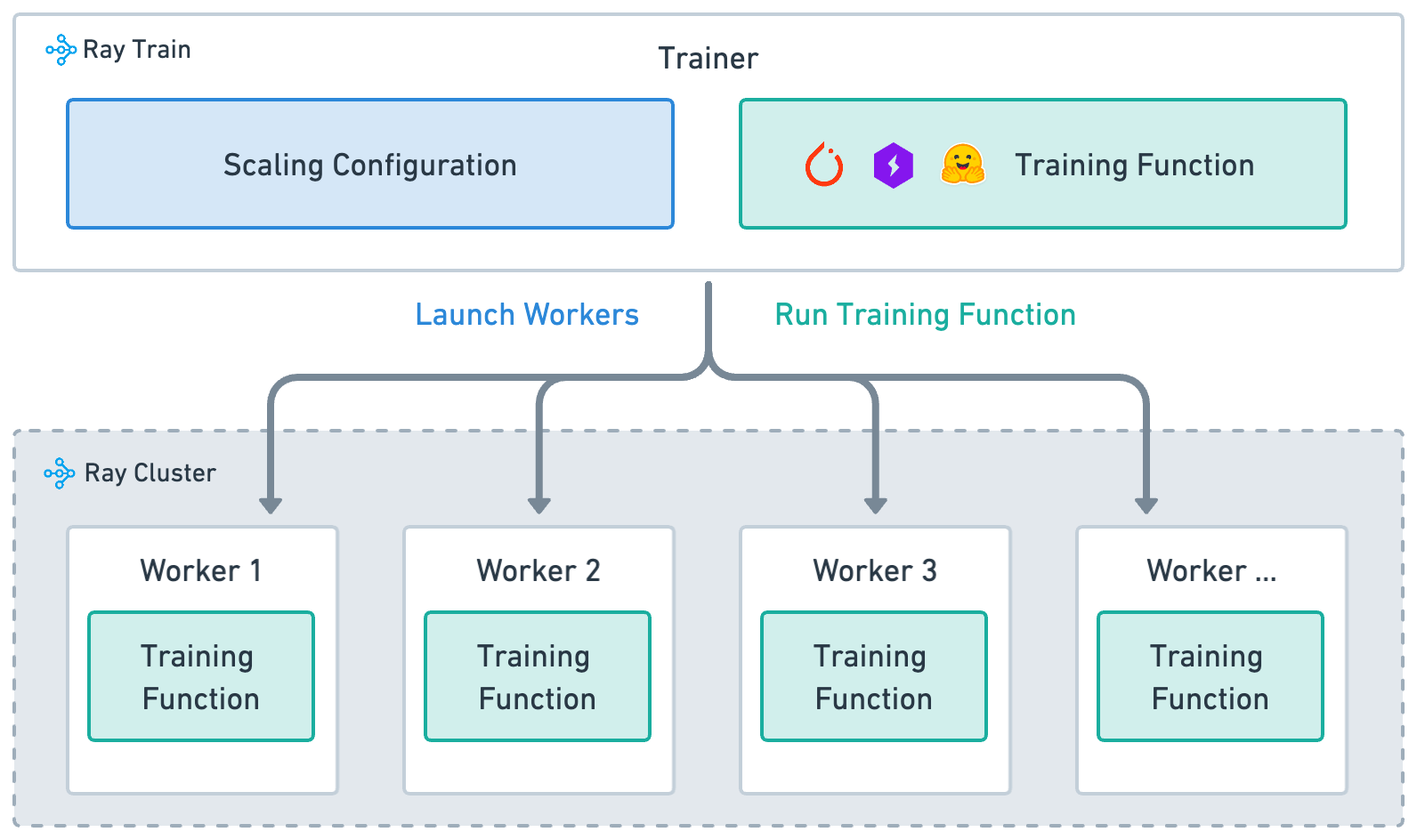
To streamline the initiation of distributed jobs on our Ray cluster, we can effortlessly submit a Ray job. Transitioning from single GPU to multiple GPUs is simplified by specifying the required number of workers in the Ray job. To achieve seamless integration with DDP and PyTorch Lightning, the final setup for our distributed training, you can check the Ray documentation.
🔗 Data Challenges in DDP
In DDP training setups, several crucial requirements must be met, including:
- proper splitting of data across nodes and devices,
- avoidance of duplicate data on devices,
- ensuring uniform data processing across all devices to maintain synchronization.
Our journey commenced with the utilization of Hugging Face datasets for data loading. However, when employed within DDP, these datasets fail to meet the aforementioned requirements due to limitations in maintaining shard counts. As a result, achieving a uniform distribution of data among workers becomes challenging, thereby impeding optimal performance. Additionally, the limited bandwidth offered by Hugging Face datasets contributes to a slowdown in overall training speed.
Enter WebDataset, a versatile library tailored for managing large datasets, featuring a TAR archive-based format for structured data storage.

The most important features of WebDataset include:
- Streaming capabilities: WebDataset enables high-speed data streaming through contiguous data chunk reading, enhancing overall performance.
- Support for diverse data sources: It seamlessly loads data from various sources such as S3, Hugging Face datasets, and Google Cloud Platform using pipe primitives, ensuring efficient data transfer.
- Flexible metadata handling: WebDataset accommodates different types of metadata formats (e.g., .json, .txt, .cls), facilitating easy integration of labels and other relevant information with the data files.
- It fully aligns with the requirements of DDP setups.
Therefore, WebDataset facilitating data loading from a MinIO instance located in close proximity to our GPU cluster, it emerged as the optimal choice.
Unfortunately, during a dry run, we encountered an issue with the setup: interruptions in streaming from MinIO occurred. WebDataset creates streaming for each device of TAR files, but these streams were prone to interruptions on the MinIO side, leading to training interruptions. To mitigate these challenges, transitioning to streaming data from the local filesystem using WebDataset proves effective. This adjustment not only addresses the interruption issue but also enhances the overall stability and reliability of the setup. By relying on the local filesystem for data streaming, we bypass potential disruptions associated with remote storage systems like MinIO.
🛠️ Powering Our Infrastructure
Having successfully tackled the complexities of distributed training, data management, and orchestration, we're thrilled to explore the foundational elements that power our infrastructure.
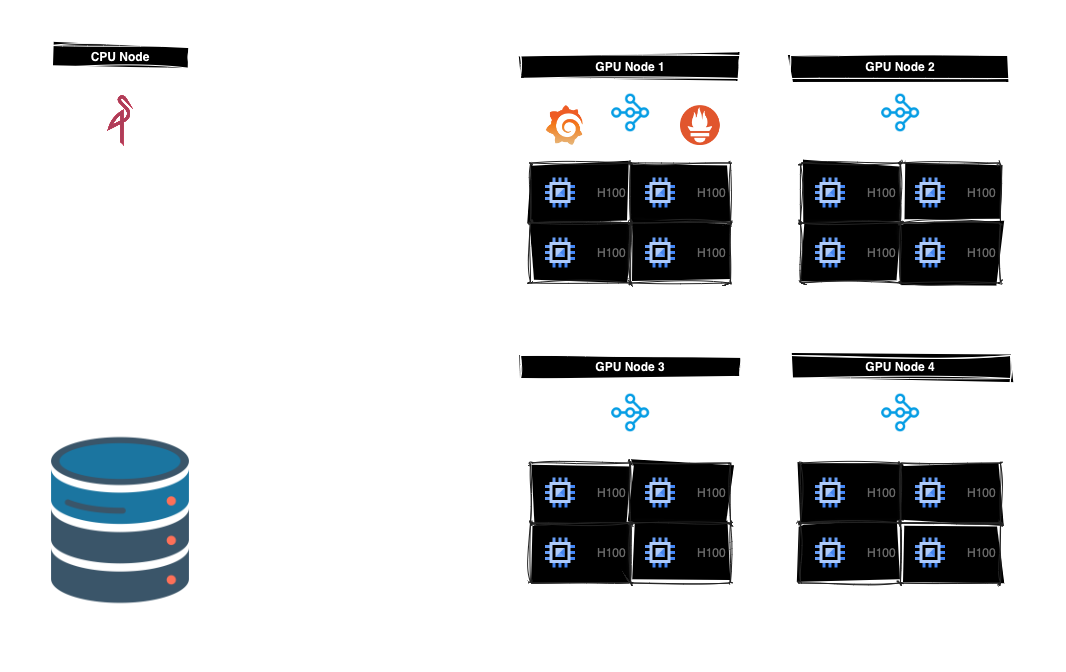
Central to our setup is a cluster configuration comprising four nodes, each equipped with four H100 80GB GPUs. Anchoring this configuration is a cohesive volume, accessible across all nodes. This shared volume serves as the centralized storage repository housing the dataset. Through the WebDataset interface, Ray workers seamlessly stream training data, ensuring consistent access and data handling throughout the cluster.
Inter-node communication is facilitated via internal IPs, optimizing data exchange among Ray workers to minimize latency and maximize throughput, thereby enhancing the efficiency of our distributed computing workflows.
While we primarily utilize WebDataset for direct data retrieval, we maintain a running instance of MinIO. Hosted on a CPU-centric node proximate to the GPU nodes, MinIO serves as a dedicated repository for storing model checkpoints, ensuring high-bandwidth access and efficient checkpoint storage.
For monitoring, Grafana and Prometheus are deployed on our Ray master node, providing comprehensive metrics directly collected by Ray for insights into resource utilization and system health. Additionally, Ray's built-in dashboard enables convenient monitoring of job status and metrics. To bolster security, firewall restrictions are enforced to thwart external access, safeguarding our infrastructure against unauthorized intrusion. All these components are powered by DataCrunch, ensuring robust performance and reliability across our training cluster infrastructure.
📺 Stay Tuned
In this blog post, we've delved into our journey of training an SLM using distributed DDP with Ray for distributed computing. Our goal is to assess whether SLMs could match larger models in performance while offering advantages such as reduced size and quicker execution. Along the way, we faced challenges including managing extensive datasets, refining data loading processes, and configuring infrastructure.
Despite these challenges, we've made substantial strides in establishing the groundwork for our foundational SLM, prem-1b. As we wrap up this phase, we're thrilled to announce upcoming releases of fine-tuned models tailored for specific tasks, such as prem-1b-chat and prem-1b-sum. These releases mark the beginning of a new era where small models are tailored to address real-world business problems effectively. Stay tuned for more innovations as we continue our quest for excellence in language understanding and generation.