Small Language Models (SLMs) for Efficient Edge Deployment
Small Language Models (SLMs) deployed on edge devices overcome cloud dependency by reducing latency, bandwidth, and privacy risks. Explores quantization, pruning, model optimization, and efficient inference for edge computing and energy efficiency.

The deployment of Small Language Models (SLMs) on edge devices has emerged as a pivotal strategy to overcome cloud dependency. This article explores how SLMs address the computational, memory, and energy constraints typical of edge hardware. We examine innovative inference techniques, model quantization, architectural optimizations, and successful use cases, emphasizing practical deployments on popular edge devices such as Raspberry Pi and Jetson Nano.
Small Language Models at the Edge
As intelligent applications become central to industries ranging from healthcare to autonomous driving, reliance solely on cloud-based AI models is increasingly problematic. While Large Language Models (LLMs) have impressive capabilities, their deployment predominantly in cloud environments poses significant challenges such as high latency, substantial bandwidth demands, and data privacy risks.
In contrast, edge computing, where computation is performed near the data source is emerging as a transformative paradigm to alleviate these limitations. Deploying AI models at the edge offers immediate processing capabilities, reduces bandwidth use, and greatly enhances user privacy by ensuring data stays local.
Limitations of Cloud Deployments
Cloud-based language model deployment often faces critical issues:
- Latency: Real-time applications like robotics, IoT control systems, and autonomous vehicles demand instantaneous decision-making capabilities. Delays inherent in cloud-based communications are unacceptable in these contexts.
- Bandwidth and Cost: Transmitting vast amounts of multimodal data (text, audio, video) to centralized cloud services is resource-intensive and costly.
- Privacy and Security: Sensitive industries such as healthcare are increasingly regulated by strict privacy standards (e.g., GDPR). Cloud transmission heightens risks of data breaches and non-compliance.
These limitations underscore the necessity of shifting towards intelligent processing directly at the data source.
Why Small Language Models (SLMs) are Essential at the Edge
Small Language Models (SLMs) represent compact, optimized versions of traditional LLMs, significantly reducing computational requirements while preserving a high degree of accuracy and performance. Unlike their larger counterparts, SLMs:
- Require considerably fewer computational resources due to smaller architectures and fewer parameters.
- Are optimized using advanced techniques like quantisation, pruning, and efficient fine-tuning allowing them to operate effectively even on devices with limited memory and computational capacities.
- Enable real-time responsiveness by processing data directly on edge devices, eliminating latency and conserving bandwidth.
- Ensure compliance with data privacy regulations by localizing sensitive data processing.
Examples such as Google's Edge TPU and various implementations in smart IoT devices demonstrate that it is feasible and beneficial to deploy SLMs directly at the data generation site. Leveraging innovative techniques like quantization, structured pruning, and adaptive inference allows for a significant reduction in model size and energy consumption, making them viable even for ultra-low-power devices.
Today, industries already deploy SLMs in scenarios including real-time healthcare diagnostics, robotics, smart homes, and autonomous navigation systems, achieving considerable performance improvements without compromising privacy or efficiency.
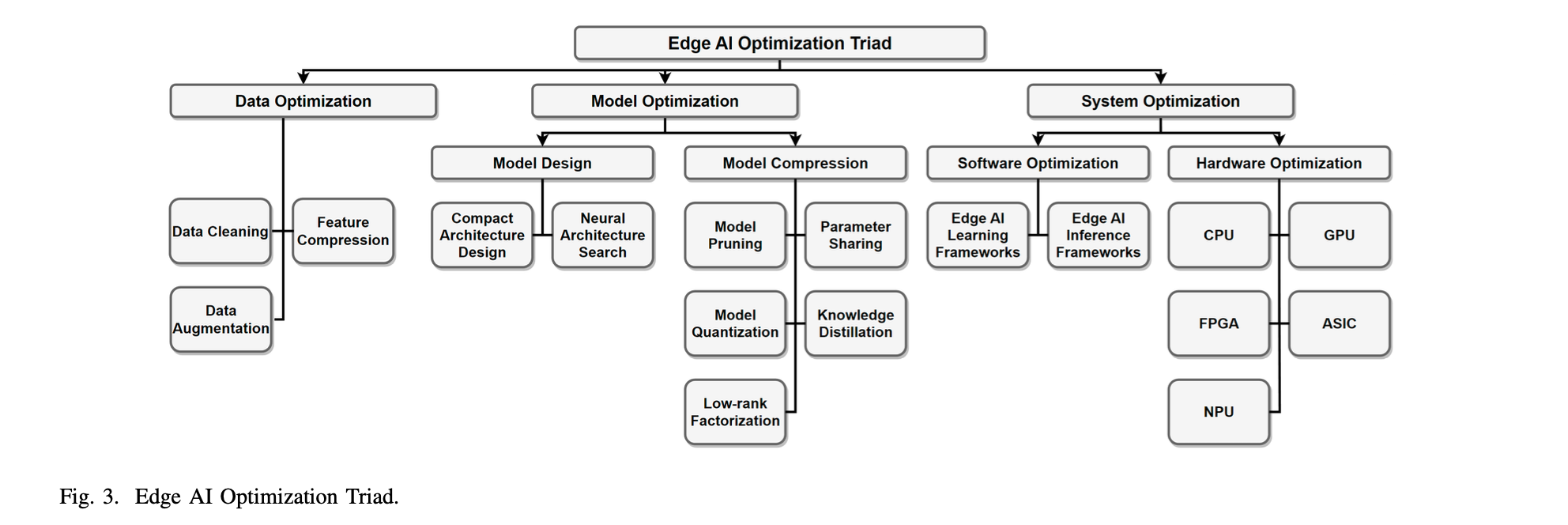
Techniques for Deploying SLMs
Deploying Small Language Models (SLMs) to edge devices involves overcoming substantial computational and storage constraints. To achieve efficient deployment, researchers and developers rely on critical optimization techniques such as model quantization, pruning, and parameter-efficient fine-tuning (PEFT). In this section, we dive deeply into these essential methods, providing practical insights and highlighting how each approach contributes to effective SLM deployment on constrained hardware.
Quantization and Pruning: Reducing Model Footprint and Computational Load
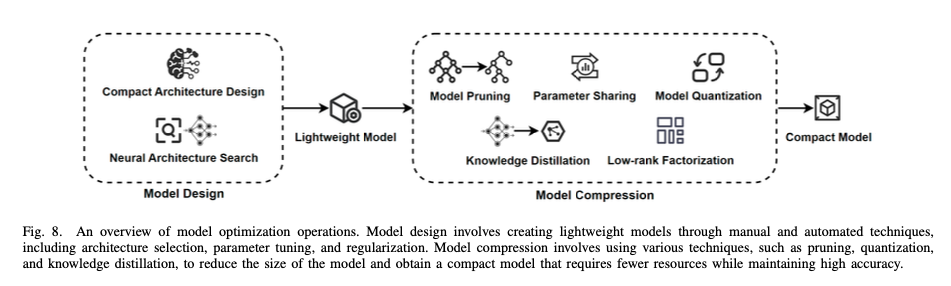
Quantization: Balancing Performance and Precision
Quantization is a fundamental technique aimed at decreasing the precision of model parameters to reduce both memory footprint and computational complexity. There are two primary methods of quantization:
- Post-Training Quantization (PTQ):
- Converts model weights from floating-point precision (e.g., FP32) to lower precision integers (INT8, INT4). This significantly decreases model size, reduces inference latency, and is highly beneficial for resource-constrained edge devices. PTQ requires no retraining, making it suitable for quick deployment scenarios.
- Quantization-Aware Training (QAT):
- Simulates the quantization process during training, enabling models to adapt to lower precision. Although QAT is more resource-intensive during training, it usually results in superior accuracy compared to PTQ, especially crucial for sensitive applications such as healthcare or precision robotics.
Quantization is particularly effective in practice. For example, quantized versions of popular models like Mistral 7B can achieve memory reductions from over 10GB to approximately 1.5GB, significantly lowering latency and enabling practical use on devices such as the Jetson Nano.
Pruning: Removing Redundancy without Sacrificing Accuracy
Pruning is a complementary optimization strategy focused on identifying and removing unnecessary parameters or neurons within neural networks, thereby significantly reducing model complexity and resource requirements. Two pruning strategies stand out in edge deployment scenarios:
- Unstructured Pruning:
- Removes individual weights throughout the network based on their importance, achieving high sparsity but potentially less optimal hardware efficiency.
- Structured Pruning:
- Removes entire neurons, channels, or layers from the neural network, directly reducing computational overhead. Structured pruning is hardware-friendly and widely adopted for edge deployments, where hardware compatibility is crucial.
Notable implementations of pruning, such as Google's BERT-Large, demonstrate that structured pruning can remove approximately 90% of network parameters with minimal accuracy loss. Similarly, the PruneBERT model achieved weight reductions up to 97% while retaining over 90% of the original accuracy, significantly speeding up inference on constrained devices.
Pruning and quantization can be combined effectively to maximize resource efficiency achieving even smaller, more computationally efficient models ideal for deployment on devices like Raspberry Pi and Jetson Nano.
Parameter-Efficient Fine-Tuning (PEFT): Adapting SLMs with Minimal Overhead
Fine-tuning large models traditionally requires substantial computational resources, often beyond the capabilities of edge hardware. To address this, Parameter-Efficient Fine-Tuning (PEFT) approaches allow updating only small subsets of model parameters, significantly reducing computational demands and storage needs.
Key PEFT strategies suitable for SLM deployment include:
Low-Rank Adaptation (LoRA): LoRA introduces low-rank matrices to pretrained models, enabling effective fine-tuning for new tasks while updating only a fraction of parameters. For instance, fine-tuning a model with LoRA typically adjusts fewer than 1% of original parameters, making it highly suitable for resource-constrained edge hardware.
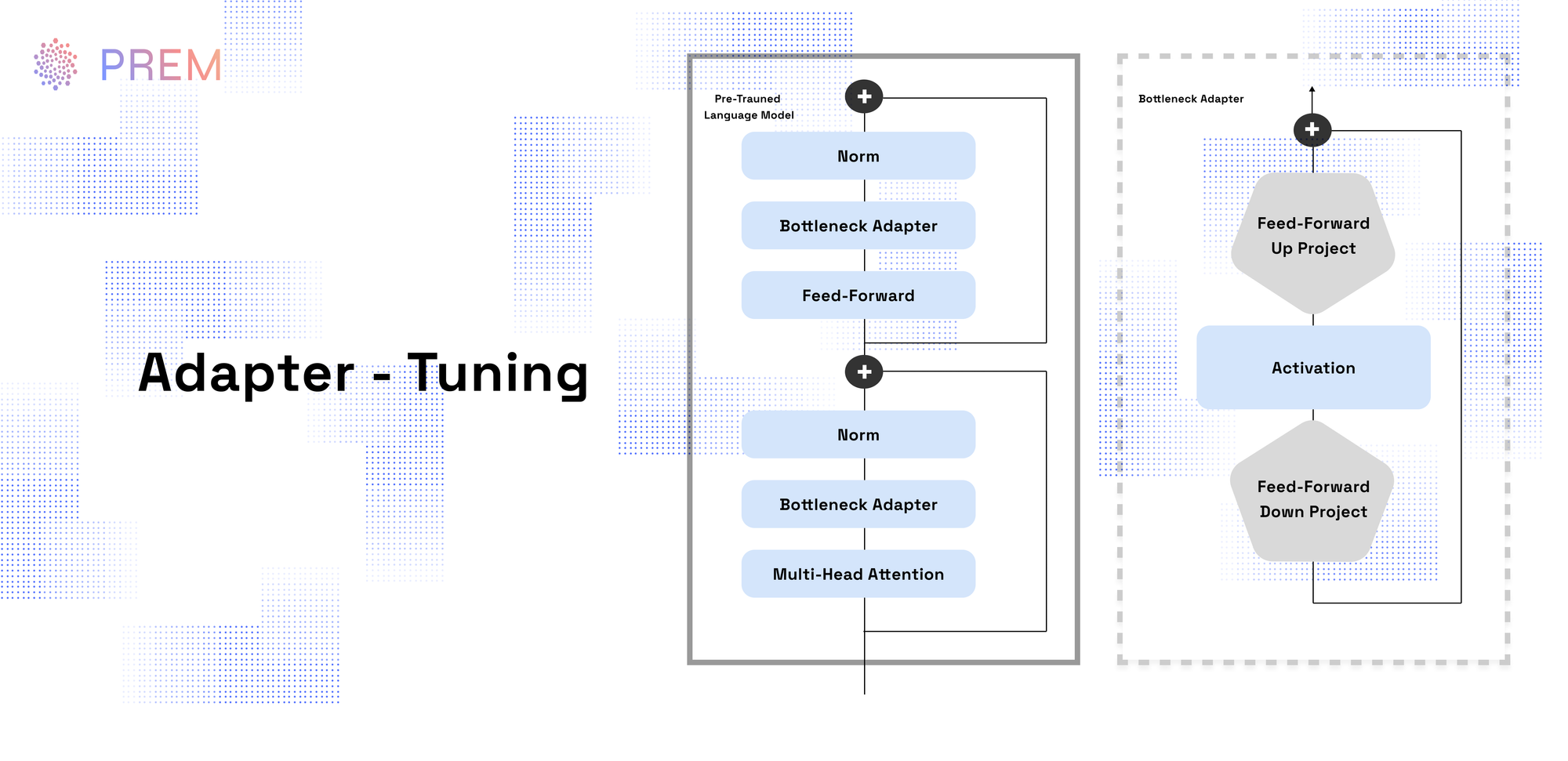
Adapter Tuning: Adapter modules are small neural network layers inserted into a pretrained model. During fine-tuning, only adapter parameters are updated, while the original model parameters remain frozen. This significantly reduces both computational overhead and storage demands, streamlining deployment to edge devices.
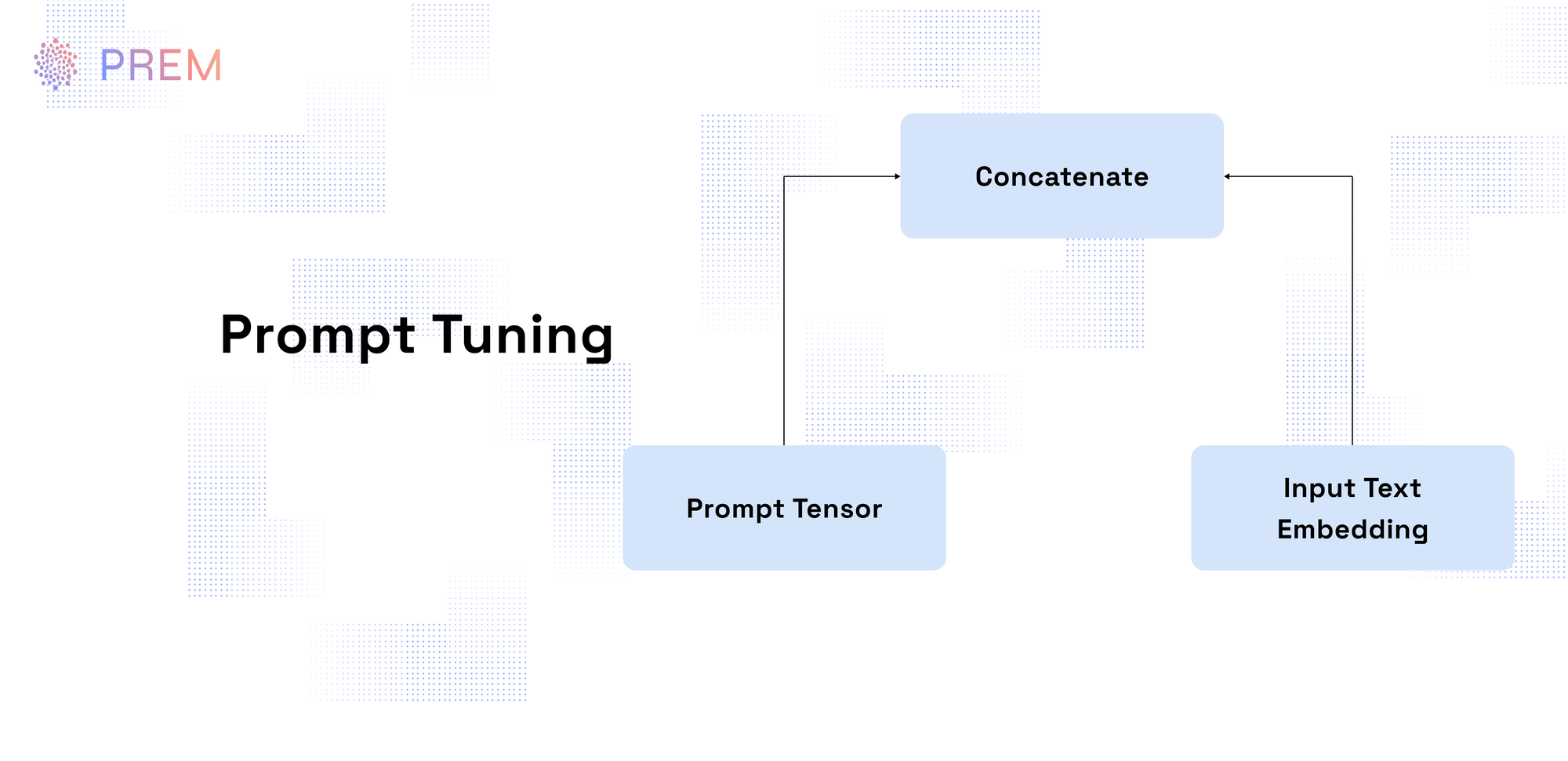
Prompt Tuning: By training only a small set of additional parameters representing “prompts,” prompt tuning modifies model behavior with minimal updates. This method is especially lightweight and ideal when quick adaptability to new tasks is required without extensive retraining.
Through PEFT, SLMs deployed at the edge can rapidly adapt to new use cases or changing environments without intensive retraining, further lowering operational costs and enabling continuous improvement in performance.
These advanced optimisation methods, quantization, pruning, and parameter-efficient fine-tuning, are critical in successfully deploying robust and efficient Small Language Models at the edge. They ensure models deliver performance comparable to larger counterparts while meeting stringent resource limitations inherent in edge computing scenarios.
Architectural and System Innovations
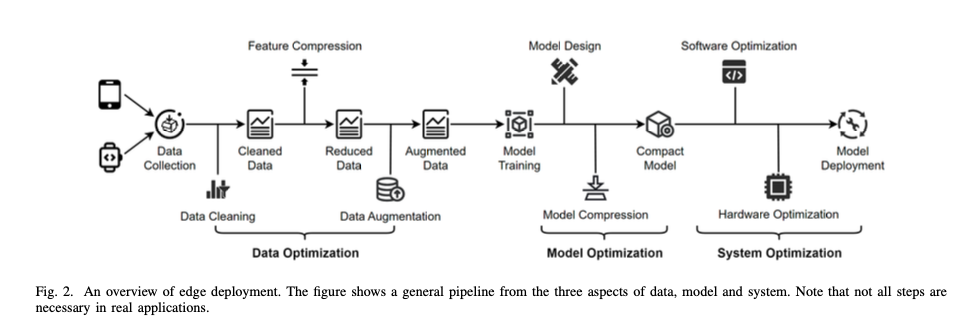
While Small Language Models (SLMs) and optimized algorithms like quantization and pruning form the foundation for efficient edge deployments, maximizing their effectiveness also depends heavily on robust architectural and system-level innovations. This section highlights key architectural strategies such as optimized edge architectures, collaborative inference methods, and intelligent caching—each crucial for ensuring high performance and scalability of SLM deployments at the edge.
Optimized Edge Architectures: AI Deployment Strategies
To fully leverage the potential of SLMs at the edge, modern architectures adopt AI-native designs, specifically crafted to meet the distinct requirements of edge scenarios. These innovative frameworks directly address latency, resource allocation, and real-time responsiveness, transforming edge devices into highly capable AI platforms.
Task-Oriented Design
Traditional cloud-centric architectures focus predominantly on throughput. Conversely, modern edge architectures prioritize low latency and immediate processing. A task-oriented design explicitly aligns resource management and computational distribution with the specific demands of real-time applications, such as autonomous robotics, IoT systems, and healthcare monitoring.
Network Virtualisation and Dynamic Resource Allocation
Effective edge deployment increasingly relies on network virtualization, utilizing centralized controllers that dynamically allocate computational resources across multiple edge nodes. This strategy significantly enhances flexibility and scalability, enabling efficient handling of diverse workloads while minimizing latency and resource wastage.
Neural Edge Paradigm
Inspired by neural network structures, the neural edge paradigm deploys individual layers or segments of an SLM across multiple edge nodes. This distributed computing approach minimizes latency and bandwidth consumption while facilitating real-time interactions across complex, interconnected systems. Such architectures are particularly suitable for scenarios involving multi-hop edge nodes, such as smart cities or industrial IoT applications.
Collaborative and Distributed Approaches
Given the inherent resource limitations of edge devices, strategies involving collaborative and distributed processing emerge as fundamental. These methods balance workload effectively among edge devices and centralized servers, enhancing performance without overwhelming individual devices.
Collaborative Inference
Collaborative inference involves splitting the inference workload between edge devices and more powerful servers. Edge nodes handle initial, lightweight processing steps, transmitting intermediate outputs to servers only when complex computations are necessary. This setup reduces both device-level computational demands and network overhead, dramatically improving efficiency, especially critical in latency-sensitive applications like autonomous driving and real-time robotics.
Federated and Split Learning
Federated learning facilitates distributed training across multiple edge devices, each processing localized data and sharing only model updates. This ensures robust model improvements while preserving data privacy. Split Learning extends this idea further, dividing the model itself between device and server, enabling both privacy preservation and efficient computational distribution. Variants such as Split Federated Learning (SFL) integrate these methods, delivering accelerated training across decentralized edge networks.
Intelligent Edge Caching and Parameter Sharing: Storage and Bandwidth Efficiency
Effective model delivery and management at the edge depend heavily on intelligent caching mechanisms and strategic parameter reuse. These techniques significantly optimize bandwidth utilization, storage requirements, and service responsiveness.
Parameter-Sharing Caching
SLMs often share substantial structural similarities across tasks. Parameter-sharing caching capitalizes on this by identifying common model components and storing them just once, drastically reducing storage demands on limited-capacity edge servers. For example, LoRA fine-tuned models often share up to 99% of parameters across different fine-tuned versions, offering massive efficiency gains when multiple task-specific models coexist at the edge.
Dynamic Model Placement and Adaptive Caching
Dynamic model placement strategies actively move frequently accessed models closer to end-users, significantly reducing access latency. Adaptive caching complements this by adjusting cached model components based on real-time task requirements and usage patterns. This adaptive strategy not only boosts overall responsiveness but also conserves valuable edge storage and bandwidth resources.
Multi-Hop Model Splitting and Distribution
For large SLMs or more complex deployments, multi-hop splitting can distribute models across several interconnected edge nodes. Each node handles part of the computation, collaboratively completing inference tasks. This approach dramatically enhances computational distribution and balances workload effectively, particularly suitable for extended IoT environments or large-scale industrial settings.
Together, these architectural and system-level innovations represent a significant step forward in deploying highly efficient, responsive, and scalable Small Language Models at the edge. Leveraging task-oriented designs, collaborative inference methods, federated learning approaches, and intelligent caching ensures edge deployments overcome resource constraints, achieve optimal performance, and deliver robust real-time intelligence.
Hardware Accelerators and Device-Specific Implementations
Optimizing Small Language Models (SLMs) for edge deployment is not solely a software-level challenge. Effective utilization of hardware-specific optimizations and accelerators plays an equally crucial role. In this section, we explore practical strategies to enhance performance on CPUs and GPUs, examine hardware acceleration using FPGA and ASIC solutions like Google's Edge TPU, and provide targeted insights for deploying optimized SLMs on widely adopted edge devices like Raspberry Pi and NVIDIA’s Jetson Nano.
CPU and GPU Optimization Techniques: Tailored Computational Efficiency
While CPUs and GPUs are fundamental to edge computing, optimizing models for these processors requires precise, hardware-aware techniques to ensure computational efficiency and minimal latency.
CPU-Based Optimization
CPUs, particularly ARM Cortex processors found in devices like Raspberry Pi, benefit significantly from techniques such as vectorization, efficient multithreading, and cache-aware programming. Frameworks optimized for CPU architectures, such as TensorFlow Lite and ONNX Runtime, deliver notable performance enhancements through optimized kernels and reduced inference latency. In resource-constrained environments, quantized and pruned SLMs particularly excel, effectively utilizing limited processing power while maintaining performance.
GPU-Based Optimization
Edge devices equipped with GPUs, such as the NVIDIA Jetson Nano, require a slightly different optimization approach. GPUs efficiently perform parallel operations but must be carefully managed to avoid memory bottlenecks. Optimizations include:
- TensorRT Integration: Leveraging NVIDIA's TensorRT library, which provides GPU-specific quantization, precision control, and operator fusion, drastically reduces inference latency and improves throughput.
- Memory Optimization: Managing batch sizes and intermediate tensor reuse to prevent GPU memory exhaustion, ensuring sustained performance even with complex, multimodal SLMs.
Together, these techniques allow effective GPU utilization, delivering fast inference suitable for real-time applications such as video analytics, robotics, and autonomous navigation systems.
FPGA and ASIC Accelerators: Specialized Hardware for Superior Efficiency
Custom accelerators, particularly Field-Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs), provide tailored solutions that further optimize the performance of SLMs at the edge.
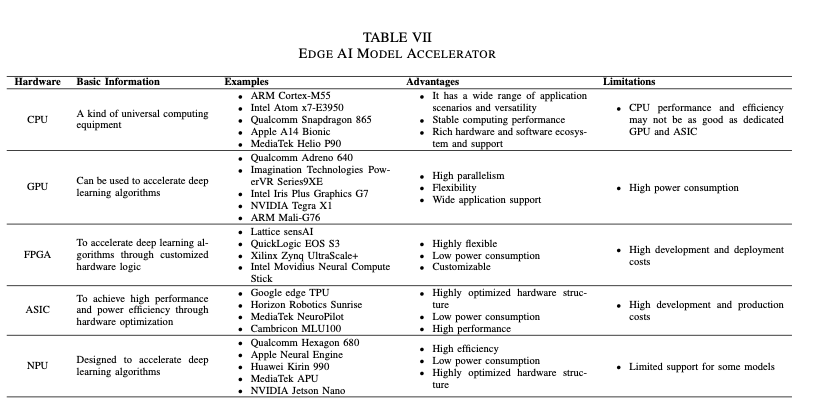
FPGA Accelerators
FPGAs, such as the Xilinx Zynq UltraScale+ or Intel Movidius devices, enable precise customization of data paths and arithmetic precision tailored to specific models. These accelerators offer unique advantages:
- Custom Parallelism: Fully exploit all levels of parallelism inherent in SLM architectures, achieving high inference speed and reduced latency.
- Adaptive Precision: Allow precise quantization tailored specifically to SLM inference needs, significantly improving computational efficiency without accuracy degradation.
Real-world deployments highlight FPGAs’ suitability in scenarios demanding customization, low latency, and energy efficiency, such as industrial automation and sensor-intensive IoT deployments.
ASIC Solutions: Google Edge TPU as a Case Study
ASIC accelerators like Google's Edge TPU offer even more specialized performance optimizations. The Edge TPU is explicitly designed for efficient inference on edge devices, incorporating quantization and structured pruning to optimize resource management dramatically:
- Quantization Efficiency: Edge TPU hardware efficiently supports INT8 quantized models, significantly reducing memory footprint and inference latency.
- Structured Pruning Support: The TPU exploits structured pruning, enabling direct hardware optimization, decreasing computational load, and conserving energy.
Edge TPUs demonstrate substantial energy savings and bandwidth optimization in practice, making them ideal for applications such as real-time image recognition, object detection in smart cameras, and autonomous robotic control.
Practical Deployments: Raspberry Pi and NVIDIA Jetson Nano
Raspberry Pi: Resource-Constrained Efficiency
Deploying SLMs on Raspberry Pi devices involves stringent resource management due to limited CPU power and memory. Effective strategies include:
- Aggressive Quantization and Pruning: Utilizing INT8 or INT4 quantization alongside structured pruning to drastically minimize model size and inference latency.
- Efficient Runtime Selection: Employing optimized runtimes such as TensorFlow Lite or ONNX Runtime, configured explicitly for ARM-based CPUs.
These optimizations make Raspberry Pi a viable platform for SLM applications, including voice assistants, home automation, and basic image processing.
NVIDIA Jetson Nano: GPU-Enhanced Performance
NVIDIA’s Jetson Nano, equipped with a capable GPU, provides opportunities for more computationally demanding edge deployments:
- GPU-Accelerated Quantization and Pruning: Leveraging TensorRT and GPU-specific optimization tools to fine-tune quantized models, significantly enhancing inference throughput and responsiveness.
- Real-Time Deployment Capabilities: Ideal for scenarios such as robotics navigation, real-time video analytics, and multimodal sensory integration, fully exploiting GPU parallelism for faster, more accurate inference.
By strategically applying hardware-specific optimizations and deploying on suitable edge devices, Small Language Models achieve superior performance, optimal resource usage, and real-world applicability across diverse edge scenarios. The combination of CPU/GPU optimizations and specialized FPGA/ASIC accelerators exemplifies the potential of modern hardware strategies in maximizing SLM efficiency at the edge.

Use Cases of Edge-Deployed SLMs
Healthcare: Real-time Diagnostics & Privacy Protection
Hospitals leverage edge-deployed SLMs for immediate processing of sensitive patient data. Models such as Google’s Med-PaLM enable real-time diagnostics and rapid decision-making without risking data breaches, significantly improving patient outcomes and compliance with privacy regulations.
Robotics: Autonomous Decision-Making
Edge-deployed SLMs empower robotics systems with instant, localized decision-making, enhancing responsiveness in industrial automation, home assistance, and autonomous navigation scenarios. Real-time object recognition and situational analysis become achievable, significantly boosting robotic performance in dynamic environments.
IoT and Smart Homes: Semantic and Context-Aware Processing
IoT devices increasingly use edge-deployed SLMs to interpret and execute user commands locally, reducing bandwidth use and increasing responsiveness. Smart assistants and home automation systems utilize SLMs to deliver personalized, context-aware responses while conserving energy and preserving data privacy.
Future Outlook: Overcoming Challenges & Embracing Innovations
While SLM deployment at the edge has demonstrated tangible benefits, key challenges persist, including computational limitations, energy efficiency, and continual model updates. Emerging solutions like contextual sparsity prediction, adaptive model architectures, and speculative decoding techniques show great promise in overcoming these challenges.
Looking forward to 2025 and beyond, edge-deployed SLMs are anticipated to become more adaptive, energy-efficient, and context-aware, leveraging continuous advancements in hardware acceleration, distributed learning frameworks, and AI-native edge architectures.
As these trends evolve, we expect edge computing will increasingly dominate the AI landscape, redefining how businesses across industries interact with intelligent technologies.
References:


