Domain-Specific Language Models: How to Build Custom LLMs for Your Industry
General LLMs struggle with specialized domains. Learn how to build domain-specific language models using fine-tuning, RAG, and evaluation. Practical guide with examples, costs, and a decision framework for enterprise AI teams.

57% of organizations estimate their data isn't AI-ready. General-purpose LLMs handle broad tasks well but hallucinate on specialized queries, miss domain jargon, and can't access proprietary knowledge. The gap between "impressive demo" and "production-ready AI model" is exactly where domain-specific language models come in.
Quick definition: a domain-specific LLM is a large language model trained or fine-tuned on data from a particular field to perform domain tasks with higher accuracy than a general model.
This is the practical guide for enterprise teams deciding how to build one, what it actually costs, and which approach fits your situation.
Why General LLMs Fall Short on Domain-Specific Tasks
General models spread knowledge thin. They know a little about everything but not enough about your field. Domain terminology gets misunderstood. "Margin" means different things in finance vs. retail. "Agent" means different things in insurance vs. AI. General models guess from context. Domain-specific models are trained on actual usage.
Proprietary context is invisible. Internal processes, compliance rules, product specs don't exist in any public training set. This is why LLM reliability drops fast when you move from general chat to specialized work.
Hallucination risk compounds in regulated industries. A wrong answer in a legal brief or clinical recommendation isn't just unhelpful. It's liability. And enterprise AI doesn't need to be unreliable to be practical.
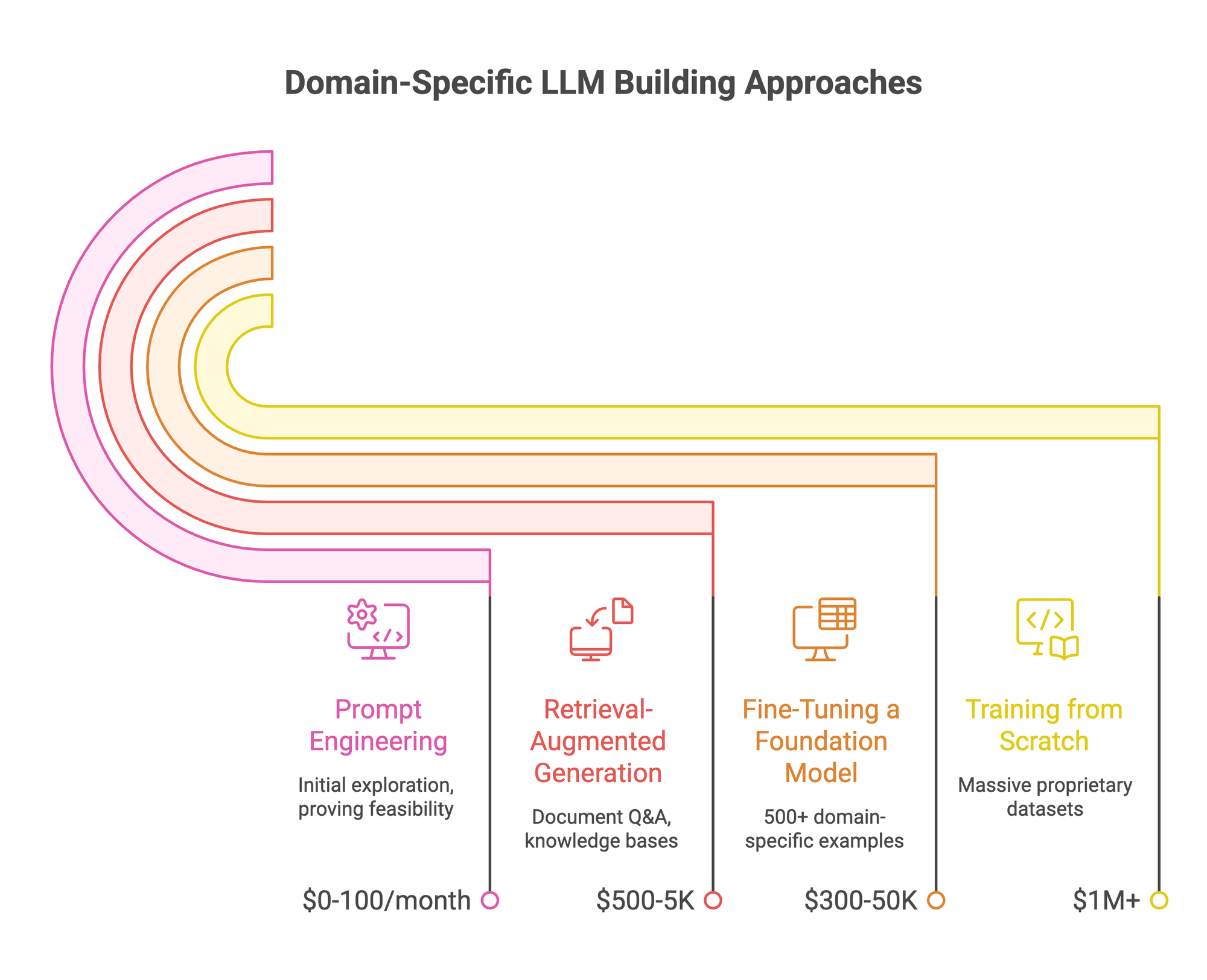
Four Approaches to Building Domain-Specific LLMs
Not every approach fits every team. Here's the full spectrum, lightest to heaviest.
Prompt Engineering (Days, $0-100/month)
- Fastest path to test domain adaptation. Craft specific prompts that guide the model toward domain outputs.
- Works for quick prototyping. Breaks down on complex, nuanced tasks.
- Context window constraints mean you can't feed the model your entire knowledge base.
- Best for: initial exploration, proving feasibility before investing in fine-tuning.
Retrieval-Augmented Generation (Weeks, $500-5K setup)
- Connects the LLM to your knowledge base through embeddings and vector search. Model retrieves relevant documents before generating answers.
- Great for dynamic data: regulations that change, product catalogs that update, support docs that evolve. There are multiple RAG strategies depending on how your data is structured, from simple keyword retrieval to agentic and graph-based approaches.
- Limitation: retrieval quality caps output quality. The model can only be as good as what it finds. And RAG vs. long-context LLMs is a tradeoff worth understanding before you commit.
- Also worth noting: RAG apps introduce their own privacy concerns when dealing with sensitive enterprise data. Where the retrieval happens and who sees the queries matters.
- Best for: document Q&A, knowledge bases, customer support with real-time info needs.
Fine-Tuning a Foundation Model (Weeks-Months, $300-50K)
The sweet spot for most enterprise teams. Take an open-source foundation model (Mistral, LLaMA, Qwen, Gemma) and train it on your domain data.
Parameter-efficient methods like LoRA make this affordable. FinGPT achieved competitive financial sentiment analysis at ~$300 per run. Compare that to BloombergGPT's $2.7M training cost.
Small language models in the 7-13B parameter range often outperform much larger general models on domain tasks after fine-tuning. There's a real conversation happening about whether open-source models are good enough for enterprise production work. Short answer: yes, when fine-tuned properly.
The SLM vs. LoRA debate matters here. Do you train a small specialized model from the ground up, or adapt a larger model with lightweight adapters? Both paths work. Your data volume and deployment constraints decide which.
This is where platforms like PremAI's Prem Studio make the process practical. Instead of stitching together Hugging Face, custom training scripts, and GPU rental, you get the full pipeline (dataset management, 35+ base models, LoRA fine-tuning, evaluation) in one workflow. More on this in the step-by-step section below.
Best for: teams with 500+ domain-specific examples who need consistent, high-accuracy output in production.
Training from Scratch (Months-Years, $1M+)
Only makes sense with truly massive proprietary datasets AND the budget to match.
Bloomberg did it: 363B tokens of financial data, 50B parameter model, 53 days of training, ~$2.7M compute, team of 9 people. They also had 40+ years of proprietary financial data nobody else could access.
Reality check: almost nobody should do this. Data distillation techniques can get you 10x smaller models with comparable accuracy through smart compression of larger models. No from-scratch training needed.
Best for: organizations with massive unique datasets and long-term strategic AI investment.
Real Examples of Domain-Specific Language Models That Work
Most guides cite BloombergGPT and Med-PaLM and call it a day. But the real signal is in the range. Domain-specific language models span billion-dollar training runs to $300 LoRA fine-tunes. The approach differs wildly. The principle doesn't: curated domain data + targeted training beats scale alone.
The cost spectrum: BloombergGPT spent $2.7M and 53 days. FinGPT gets competitive financial sentiment analysis from a LoRA fine-tune at roughly $300 per run. The difference? Bloomberg had 40 years of proprietary financial data nobody else could access. FinGPT works with publicly available data and parameter-efficient fine-tuning. Most enterprise teams are closer to the FinGPT end of the spectrum. And that's fine.
PremAI's own models prove the pattern: PremAI built Prem-1B-SQL, a 1.3B parameter model fine-tuned from DeepSeek Coder specifically for Text-to-SQL tasks. It runs fully locally, uses execution-guided decoding (if the generated SQL throws an error, the model self-corrects and retries), and handles real-world database queries that general LLMs fumble. A 1.3 billion parameter model doing what much larger models can't. That's domain-specific fine-tuning at work.
Enterprise customers, not just research labs: Grand, a subsidiary of Advisense serving approximately 700 financial institutions, used Prem Studio to fine-tune models for regulatory compliance. What used to require manual review now runs through a domain-specific model that processes documents at scale with 100% data residency compliance. Sellix, an e-commerce platform, used PremAI's integrations to build a fraud detection model that's over 80% more accurate at spotting fake transactions. Neither company had ML engineering teams. They had domain data and the right platform.
What the pattern tells you: The takeaway across all these examples: you don't need to train from scratch. Open-source models in the 1B-13B range, fine-tuned on curated domain data, consistently match or beat larger general models on specialized tasks. The variable that matters most isn't model size. It's data quality and evaluation rigor.
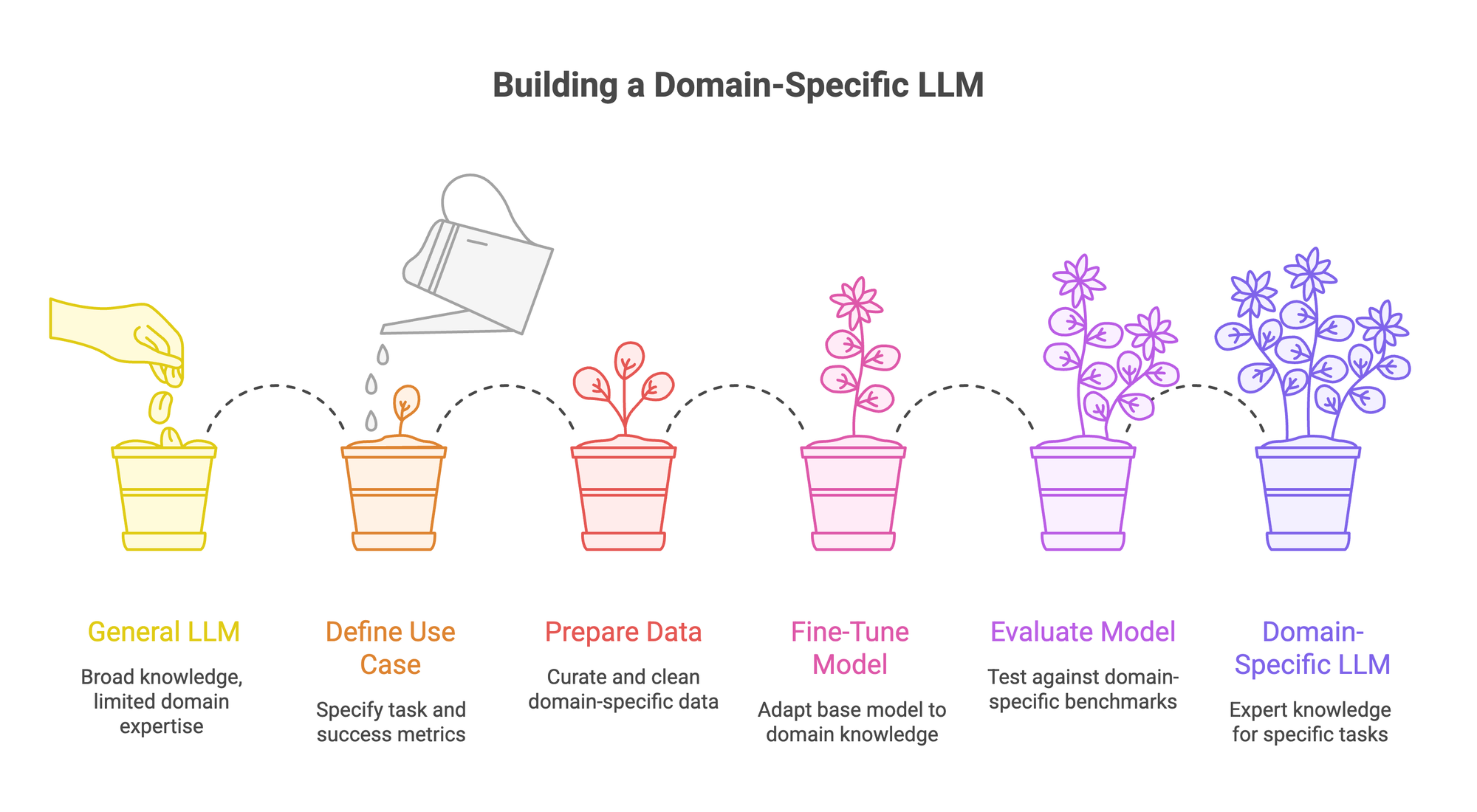
How to Build a Domain-Specific LLM: Step by Step
The theory is straightforward. The execution is where teams get stuck. Here's the full workflow, step by step, with the practical "how" for each stage. We'll use Prem Studio as the implementation layer since it handles the end-to-end pipeline: datasets, fine-tuning, evaluation, and deployment in one platform. But the principles apply regardless of tooling.
Step 1 - Define Your Use Case and Success Metrics
- Pick one specific task. Not "make AI work for us." Something like: "Answer compliance questions with >90% accuracy" or "Classify support tickets by product category with <5% error rate."
- Identify who evaluates outputs. Domain experts, not just engineers. A model that sounds fluent to an engineer might be dangerously wrong to a compliance officer.
- Set baseline measurements. Run your target queries through a general-purpose LLM first. Document where it fails. That failure set becomes your fine-tuning priority and your evaluation benchmark.
Step 2 - Curate and Prepare Your Domain Data
General guidance:
- Quality beats quantity every time. Even 500-2,000 high-quality examples meaningfully improve domain performance.
- Sources: internal docs, product manuals, support tickets, regulatory filings, domain-specific Q&A pairs.
- Clean the data: remove PII, deduplicate, validate with domain experts.
With PremAI:
Prem Studio's Datasets module handles this in two ways:
Option A - You already have data: Upload your existing dataset in JSONL format. Each line is a conversation example with system, user, and assistant messages. Drag and drop. The platform handles formatting validation.
Option B - You have documents, not datasets: This is where most enterprise teams actually start. You have PDFs, DOCX files, internal wikis, maybe some YouTube training videos. Prem Studio can generate synthetic datasets directly from these sources. Upload your regulatory PDFs, product documentation, or support transcripts. The platform extracts content and creates question-answer training pairs automatically.
Either way, you then:
- Enrich your dataset with synthetic data augmentation (configurable creativity level, positive/negative instructions for what to generate more or less of)
- Auto-split into training, validation, and test sets
- Create a snapshot (versioned checkpoint of your data before training)
PII redaction is built in. Dataset generation typically takes 10-30 minutes depending on source volume.
The autonomous fine-tuning system includes built-in augmentation so you're not stuck with only the examples you already have. For teams with limited domain data, synthetic data generation fills the gap.
Step 3 - Choose Your Base Model and Fine-Tune
General guidance:
- Start with 7-13B parameter open-source models (Mistral, LLaMA, Qwen, Gemma).
- LoRA/QLoRA for parameter-efficient fine-tuning. Full fine-tuning is overkill for most domain adaptation.
- The SLM vs. LoRA tradeoff matters: train a small specialized model from scratch, or adapt a larger model with lightweight adapters? Your data volume and deployment constraints decide.
With PremAI:
Prem Studio offers 35+ open-source base models including LLaMA, Qwen, Gemma, Phi-3, and others. The workflow:
- Create a Fine-Tuning Job. Name it, select your dataset snapshot.
- Pick your base model. You can compare multiple models in parallel. Prem supports running concurrent experiments on different bases so you're not guessing which model works best for your domain.
- Choose your method. QLoRA, LoRA, or full fine-tuning. For most domain adaptation, LoRA gets you there faster: if standard fine-tuning takes 30 minutes, LoRA often finishes in 10 minutes or less.
- Alignment tuning (optional). For tasks where the model needs to follow specific intent patterns, Prem supports GRPO and DPO to reinforce accuracy and alignment beyond basic fine-tuning.
- Toggle synthetic data generation if you want the autonomous fine-tuning agent to expand your dataset during training. Configure creativity level, positive instructions (what to generate more of), negative instructions (what to avoid).
The platform emails you when training starts and when it completes. A typical fine-tuning run takes 30 minutes to 2 hours depending on model size and dataset.
For teams building smaller, faster models: PremAI supports knowledge distillation to compress a larger model's domain knowledge into a smaller one. Small models deliver big wins when the distillation is done right: 50% inference time reduction, 70% per-token cost savings.
Hyperparameters matter for domain accuracy. Low learning rate, 3-5 epochs, temperature 0.0-0.3 for factual domain tasks. Custom reasoning models need different tuning than classification or extraction tasks. DeepSeek R1's open-source approach proved this path is viable at scale.
Step 4 - Evaluate with Domain-Specific Benchmarks
- Generic benchmarks (MMLU, HumanEval) won't tell you if your model works for your domain.
- Build custom evaluation criteria with domain experts.
- Enterprise AI evaluation means testing on held-out data, checking hallucination on edge cases, and running side-by-side comparisons.
- Don't skip this. Teams that go straight from fine-tuning to deployment debug in production. That's expensive.
With PremAI:
Prem Studio's Evaluations module is where you define what "good" means for your domain:
- Create custom metrics in natural language. You don't write code. You describe what the evaluator should look for. Example for invoice parsing: "Ensure the output is in correct JSON format, matches the ground truth, and contains all keys the user requested." Prem auto-generates specific judging rules from your description.
- Use built-in metrics (Conciseness, Hallucination detection) alongside your custom ones.
- Run LLM-as-judge evaluations that score your fine-tuned model against your criteria.
- Compare models side-by-side. Fine-tuned vs. base model. Fine-tuned vs. closed-source (GPT-4, Claude). This is how you know if your domain model actually outperforms the alternatives on the tasks that matter.
Evaluation typically takes 5-15 minutes. Results tell you exactly where the model excels and where it needs more data.
The loop is the key: Evaluate → identify weaknesses → expand dataset in those areas → fine-tune again → re-evaluate. Prem's project workflow is built for exactly this iteration: Dataset Expansion → More Fine-tuning Jobs → New Metrics → Re-evaluation. Also check LLM evaluation benchmarks and challenges for broader context on what evaluation methods exist.
Step 5 - Deploy and Keep the Model Current
General guidance:
- Deployment isn't the finish line. Domain knowledge drifts. Regulations change, products update.
- Plan for continual learning.
- Data sovereignty matters. Where the model runs is as important as how well it performs in regulated industries.
With PremAI:
Three deployment options:
- Prem Cloud: Models are automatically deployed on Prem infrastructure after fine-tuning. Zero setup. Start using your model immediately via PremAI SDK (Python/JavaScript) or OpenAI-compatible API.
- Self-hosted: Download your fine-tuned model checkpoints. Deploy with vLLM, Ollama, HuggingFace Transformers, or NVIDIA NIM. You own the weights. Full portability.
- Enterprise (VPC/On-premise): One-click deployment to your AWS VPC or on-premise infrastructure. Swiss jurisdiction (FADP), SOC 2, GDPR, HIPAA compliant. Zero data retention. Cryptographic verification for every interaction. Your domain data never leaves your environment.
100% model ownership regardless of deployment option. Models built on Prem Studio can always be exported and self-hosted.
For keeping the model current: the same dataset → fine-tune → evaluate loop applies. When your domain data shifts (new regulations, updated product specs, new compliance requirements), upload new data, run a new fine-tuning job, evaluate against your existing metrics, and redeploy.
Running a smaller fine-tuned model instead of routing everything through GPT-4 or Claude can save up to 90% on inference costs while giving you better accuracy on your domain tasks.
Which Approach Should You Pick?
Key insight: most enterprise teams should start with RAG for quick wins, then layer fine-tuning on top for production accuracy. Training from scratch is rarely justified.
And here's what most guides won't tell you: the biggest bottleneck is the data preparation and evaluation loop. Teams that invest in dataset quality and rigorous evaluation before scaling up save months of rework.
FAQ Section
What is a domain-specific LLM?
A domain-specific LLM is a large language model trained or fine-tuned on data from a particular industry or field. Unlike general-purpose models, it understands domain terminology, compliance requirements, and specialized workflows, delivering higher accuracy on tasks within that domain.
How much does it cost to build a domain-specific language model?
Costs range widely. Fine-tuning with LoRA can cost as little as $300 per run. Training from scratch cost Bloomberg approximately $2.7M. Most enterprise teams spend $5K-50K on fine-tuning for production results. Platforms like Prem Studio offer usage-based pricing through AWS Marketplace, so you're not committing to infrastructure upfront.
Can small language models be domain-specific?
Yes. Smaller models (7-13B parameters) often outperform larger general models after domain fine-tuning. They're faster to train, cheaper to deploy, and easier to run on-premise for data sovereignty.
What data do I need to build a domain-specific LLM?
Curated, domain-relevant data: internal documents, product manuals, regulatory filings, Q&A pairs, support transcripts. Quality matters more than quantity. Even 500-2,000 high-quality examples can meaningfully improve domain performance.
Should I use RAG or fine-tuning for my domain-specific LLM?
Use RAG when your knowledge base changes frequently. Use fine-tuning when the model needs to internalize domain reasoning and compliance patterns. Many production systems combine both for best results.
Conclusion
Tie back to the opening. General-purpose LLMs are starting points, not endpoints. Specialized domains need specialized models. The good news: open-source foundation models + quality domain data + parameter-efficient fine-tuning gets most enterprise teams 80-90% of the way there.
The practical path: curate your domain data, fine-tune a small language model, evaluate rigorously, deploy where your data stays under your control.
Prem Studio brings this full workflow (datasets, fine-tuning, evaluation, deployment) into one platform with 35+ base models, autonomous fine-tuning, and enterprise-grade data sovereignty. Book a demo to test it on your domain data, or explore the docs to get started.