
Introducing Prem-Operator, An Open-Source Kubernetes Operator for AI/ML
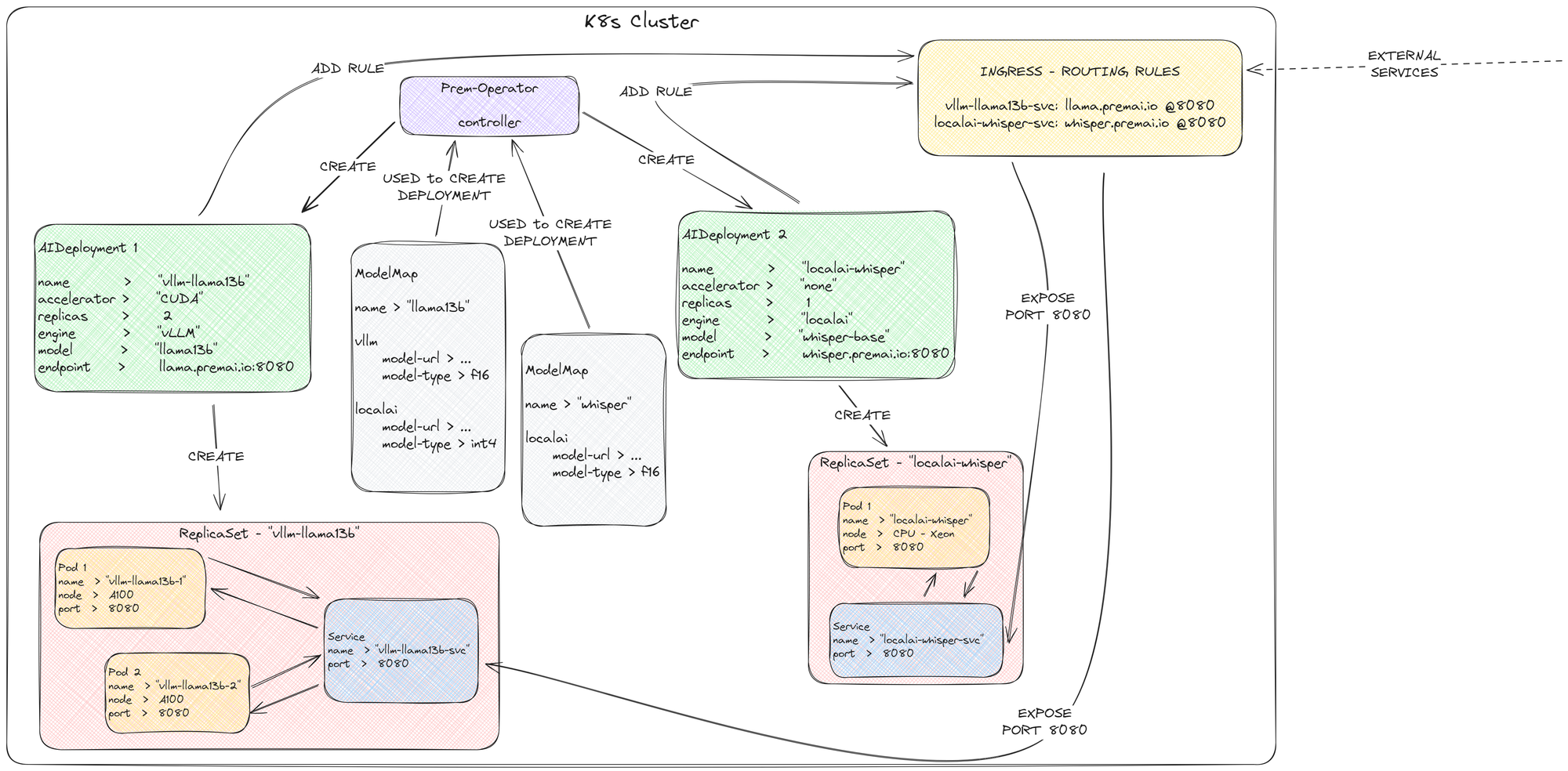
Today, we are excited to announce the open-source release of the “Prem-Operator,” A Kubernetes operator that eases the deployment of AI and ML workloads, with an initial focus on inference.
The launch of the Prem Operator marks a major advancement in our goal to provide AI that you can fully own. This component is a key element in our wider strategy to simplify the deployment of controllable AI.
We also use it to collect and showcase things you can quickly do with AI on Kubernetes. Head over to the repository to see what you can do, for example:
Local GPT Interface deployment
Prem Operator is a simple component that serves as a building block in a broader and far-encompassing vision to make deploying AI that you can control easy. This is part of Prem’s long-term mission to help build AI that you can have complete ownership of.
While the benefits of having control over your AI/ML systems are straightforward to many, the road to widespread adoption is fraught with complexities and hard-to-avoid mistakes. Deploying and scaling AI workloads across diverse environments has remained a daunting challenge, often requiring specialized expertise and extensive resources.
Despite significant advancements in open-source initiatives and AI/ML technologies, many enterprises have yet to adopt AI due to the complexities involved in deploying models internally for production use.

🎯 Our Motivations
While it's certainly possible to deploy any machine learning framework within a container on Kubernetes, just like any other application, our experience has shown that certain patterns and best practices are consistent across AI deployments. Adherence to these patterns can often result in obscure errors during the application lifecycle, leading to hours or even days of troubleshooting to identify and resolve arbitrary configuration issues.
We aim to address these challenges by providing structure around AI/ML deployments targeted for Kubernetes. Thus, common pitfalls can be avoided when deploying similar workloads to Kubernetes without unnecessarily limiting the underlying workload.
For instance, while LocalAI and Triton have distinct architectures and capabilities, we recognize that their deployment configurations share certain commonalities. By identifying and leveraging these shared patterns, we can offer a more consistent deployment experience without compromising each engine's unique features or functionalities.
Our approach is not to create an API compatibility layer or force a lowest standard denominator solution. Instead, we focus on exposing the native features and capabilities of the underlying engines, allowing users to take full advantage of their respective strengths and innovations. This means that when the engine providers introduce new features, we can seamlessly incorporate them into our deployment workflows without requiring extensive modifications to compatibility layers. This also makes it much easier for us to add new and innovative solutions to our line-up of supported models and libraries without much additional effort.
In comparison to alternatives such as KServe, it lacks many features and does not attempt to solve problems that we feel are primarily of concern to a small minority of inference service providers. The result is that there is far less irrelevant information to digest when working with the Prem Operator.
🤔 But why Kubernetes?
While we understand that Kubernetes introduces a steep learning curve, it’s the industry standard for deploying horizontally scalable and highly available services. It has a vast ecosystem for deploying every type of distributed service, and AI/ML is no different.
Kubernetes offers the flexibility to deploy AI models across hybrid and multi-cloud environments, enabling you to leverage the benefits of different cloud providers or on-premises resources when needed. Of note is also that Kubernetes provides a consistent and portable platform for deploying AI models across different environments, such as on-premises data centres, public clouds, or hybrid setups. This consistency simplifies the deployment process and reduces the risk of environment-specific issues.
🌳 The Now of the Project?
The Prem-Operator is in its early stages, with several rough edges and unimplemented ideas. Some features may be removed as, ultimately, the project will be driven by what is useful in our broader vision and what can be maintained to a high quality.
While our operator is a component in a broader architecture, it is usable independently. It comes with various examples and project specific quick-start guides. The purpose is to give platform engineers an anchor point when starting up an AI/ML GPU deployment with minimal effort, and mistakes.
🚀 Quick Start Guide:
You can start with our the documentation on our repository. But if you have a Linux box with an nvidia GPU attached, you can go ahead and follow along.
- Start with a Kubernetes cluster, with an NVIDIA GPU(at least 8GB VRAM), and ensure you have nvidia-container-toolkit installed on the host system.
# install docker desktop and enable k8s support
# from: https://docs.docker.com/engine/install/
# or, you can also install k3s
# download the script
wget https://raw.githubusercontent.com/premAI-io/prem-operator/ed1c955274520d6a94277fb8508e3ec21c5db704/script/install_k3s.sh
# run the script
sh install_k3s.sh
# also ensure you have nvidia-container-toolkit installed
# https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
# most cloud gpu providers should already have it installed- Install the NVIDIA Operator, currently required for GPU support for workloads.
# make sure you have helm installed
# you can follow, https://helm.sh/docs/intro/install/
# add the nvidia chart repo
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
# install the operator from the helm chart
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator- Deploy the Prem Operator using Helm:
helm install --wait \
-n prem-operator --create-namespace \
prem oci://registry-1.docker.io/premai/prem-operator-chart \
--version 0.10.1- Run the Hermes + Big-AGI example to see it in action:
# make sure kubectl is installed
# you can follow https://kubernetes.io/docs/tasks/tools/#kubectl
kubectl apply -f https://raw.githubusercontent.com/premAI-io/prem-operator/ed1c955274520d6a94277fb8508e3ec21c5db704/examples/big-agi.yaml# use kubectl port-forwarding, or you can setup an ingress controller
# @ https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/
kubectl port-forward services/big-agi-service 3000:3000- Open
http://localhost:3000to interact with your AI model as soon as it’s ready!
💖 Get Involved:
We're looking for feedback, contributors, and enthusiasts to join our community. Drop us a line on Prem's Discord in the “#operator” channel, or start a thread on our project's GitHub!