Introducing Benchmarks v2
Prem's Benchmarks v2 is an open-source project evaluating 13+ LLM inference engines, including vLLM and TensorRT LLM, across precisions like float32, float16, int4, and int8. It helps the open-source community and enterprises understand LLM inference performance.
We believe in giving back to the community. So today we introduce Prem Benchmarks. This is a fully open-source project with its primary objective being to benchmark popular LLM inference engines (currently 13 + engines) like vLLM, TensorRT LLM, HuggingFace Transformers, etc on different precisions like float32, float16, int4, and int8. We benchmark w.r.t. different parameters of comparison, hoping to give the open-source LLM community and enterprises a better idea of LLM inference metrics. The benchmarks are exclusively dedicated to comparing distinct open-source implementations. Don't forget to star this repository and follow Prem. We are constantly improving and adding benchmarks for newer engines.
 premAI-io
premAI-io🤔 But Why Benchmarks
You might wonder why one open-source repository is comparing other open-source implementations. Ultimately, it all boils down to making important decisions and the cost associated with those decisions. The final goal is to decide on an option that fulfills our requirements, is cost-effective, and delivers the quality we expect. Benchmarks aim to encompass all these aspects. To be specific, here are three pointers that summarize the need for benchmarks:
- Choices vs fulfilling requirements: Inference engines mostly provide some optimizations, either in terms of latency, lowering memory usage, or sometimes both. However, in the current market, we have a lot of options, so it is hard to understand which would be best suited for our current requirements. For example, suppose you have limited resources in terms of GPU, but still, you need to fit LLama/Mistral kind of LLMs. Instead of trying out solutions offering quantizations from scratch, you can reference this repository as a good starting point to filter the options
- Reproducible, hackable, and extensible: Many times, we encounter numbers in theory, and sometimes they might be a bit misleading. So, another motivation for building this open-source project is to have a fully transparent source of truth that is reproducible. Not only are each of the inference engines well-documented (more on this later) - which helps developers to not only sort or filter out choices - but also provides a reference implementation that they can use to write their deployment pipelines. For example, installing TensorRT LLM can be a bit of a pain. However, our scripts are robust enough to handle some of the issues. You can use them for your inference pipelines.
- The trade-off between quality and quantity: Last but not least, it is quite natural that optimizations come with a certain cost. If your optimizations provide faster inference, this means that it could result from quantization, custom kernels, or algorithms (like paged attention used by vLLM). Quantization can sometimes lead to a loss in the quality of generations since we are using integer approximations of floating-point numbers. As for the latter, we might compromise vRAM consumption. In this blog, we are going to discuss all these observations and trade-offs, which you can also use as a reference to make quality choices.
🚀 The Benchmarking process
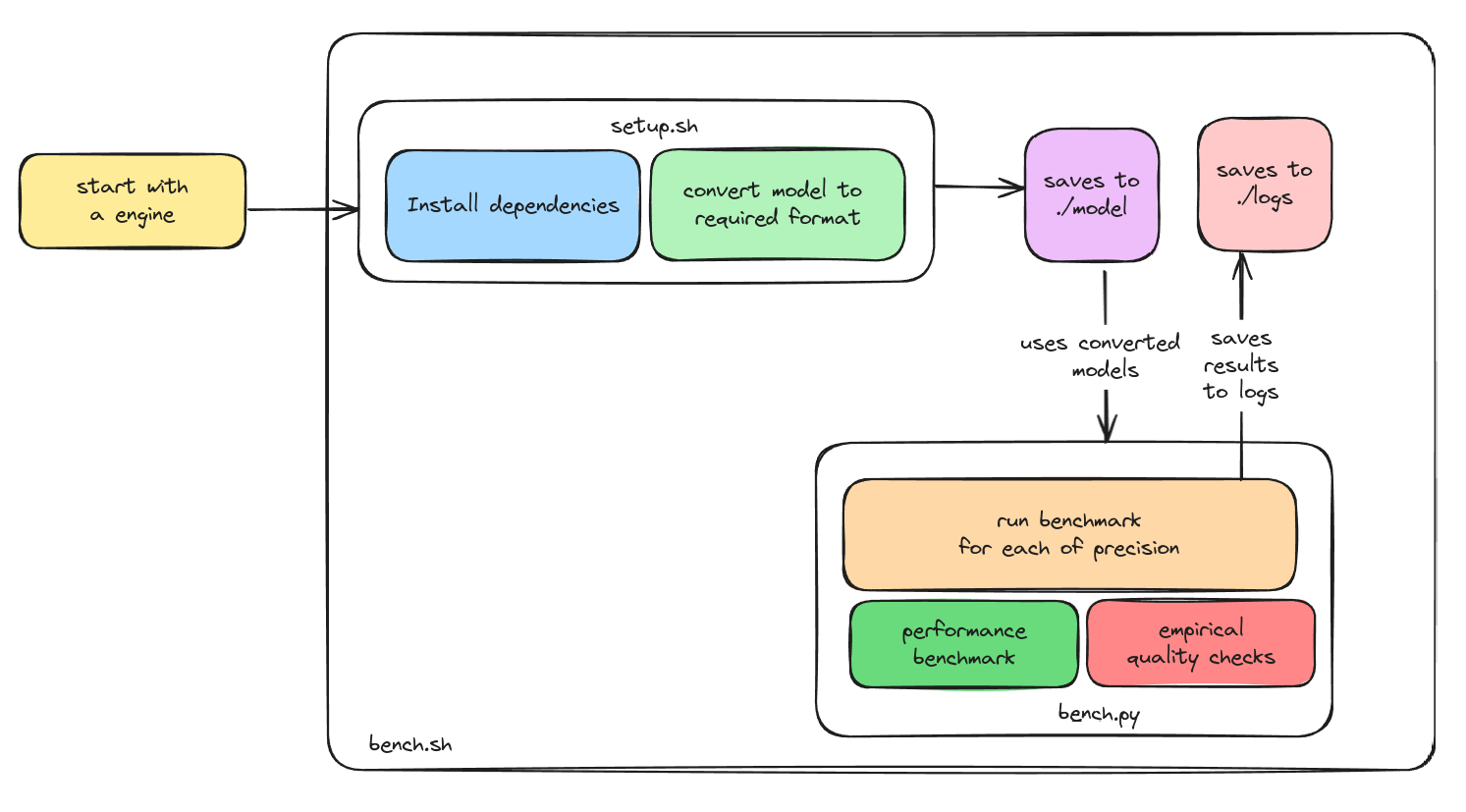
Our benchmarking process is simple. We refer to each implementation as an 'engine'. Each engine has its dedicated folder structure. Each of them will have these four files in common. Here is an example:
bench_deepspeed/
├── bench.py
├── bench.sh
├── README.md
├── requirements.txt
└── setup.shThe Python file contains the main benchmarking logic, setup.sh contains the scripts to install. bench.sh contains the script that we are supposed to run which will take care of installation and benchmarking and providing the results. README.md file contains the following:
- A quick introduction to the engine. For example, vLLM will contain info about what it is, along with some important links.
- The instructions on how to run the specific benchmark, although they are the same for most of them.
- A qualitative comparison of the results. Simply, we compare LLMs generation from different engines across their respective supported precisions with the raw LLM weights (float32) precision. This helps to assess how many generations were affected by changes in engine and precision. More about this in the next section.
- Last but not least, a set of pointers that contain nuances associated with that very benchmark.
Running a benchmark
If you are interested in running or reproducing a benchmark, then first go ahead and clone the benchmarks repository. Download the models using ./download.sh a script. Running each benchmark has this common set of CLI arguments.
-p, --prompt Prompt for benchmarks (default: 'Write an essay about the transformer model architecture')
-r, --repetitions Number of repetitions for benchmarks (default: 10)
-m, --max_tokens Maximum number of tokens for benchmarks (default: 512)
-d, --device Device for benchmarks (possible values: 'metal', 'cuda', and 'cpu', default: 'cuda')
-n, --model_name The name of the model to benchmark (possible values: 'llama' for using Llama2, 'mistral' for using Mistral 7B v0.1)
-lf, --log_file Logging file name.
-h, --help Show this help messageNow, all you have to do is choose which one to run and use these commands for some customization. Here is an example:
./bench_tensorrtllm/bench.sh -d cuda -n llama -r 10Once you run, our code will take care of the installation and do the benchmark. Once the benchmarking is finished, you can find the results of the run inside our logs/model_name folder (in the above case it will be logs/llama folder). Each logs have the following folder structure:
Nvidia-TRT-LLM-2024-04-24 08:16:01.620963/
├── performance.log
├── quality.md
└── quality_check.jsonThe logs are created w.r.t name of benchmark, date, and time of creation. The performance.log file contains the information about the runs and stores the speed (tokens/sec) and the GPU consumption (in MB). quality.md is a nicely formatted readme table (made from quality.json ) which contains the qualitative comparisons, similar to the table shown in Figure 1.
So to recap, here is a simple diagram that shows the whole benchmarking process
🛳 ML Engines
Before proceeding further with the analysis and our findings. Here is our ML Engines table which gives a bird's eye view of the support matrix of the benchmarks repository:
| Engine | Float32 | Float16 | Int8 | Int4 | CUDA | ROCM | Mac M1/M2 | Training |
|---|---|---|---|---|---|---|---|---|
| candle | ⚠️ | ✅ | ⚠️ | ⚠️ | ✅ | ❌ | 🚧 | ❌ |
| llama.cpp | ❌ | ❌ | ✅ | ✅ | ✅ | 🚧 | 🚧 | ❌ |
| ctranslate | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | 🚧 | ❌ |
| onnx | ✅ | ✅ | ❌ | ❌ | ✅ | ⚠️ | ❌ | ❌ |
| transformers (pytorch) | ✅ | ✅ | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| vllm | ✅ | ✅ | ❌ | ✅ | ✅ | 🚧 | ❌ | ❌ |
| exllamav2 | ❌ | ❌ | ✅ | ✅ | ✅ | 🚧 | ❌ | ❌ |
| ctransformers | ❌ | ❌ | ✅ | ✅ | ✅ | 🚧 | 🚧 | ❌ |
| AutoGPTQ | ✅ | ✅ | ⚠️ | ⚠️ | ✅ | ❌ | ❌ | ❌ |
| AutoAWQ | ❌ | ❌ | ❌ | ✅ | ✅ | ❌ | ❌ | ❌ |
| DeepSpeed-MII | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ⚠️ |
| PyTorch Lightning | ✅ | ✅ | ✅ | ✅ | ✅ | ⚠️ | ⚠️ | ✅ |
| Optimum Nvidia | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| Nvidia TensorRT-LLM | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
Legend:
- ✅ Supported
- ❌ Not Supported
- ⚠️ There is a catch related to this
- 🚧 It is supported but not implemented in this current version
The above table gives us an overall summary. For ⚠️ and 🚧, we have a summary of possible reasons explaining all the nuances responsible:
| Name | Type | Description |
|---|---|---|
| candle | ⚠️ | Metal backend is supported but it gives terrible performance even in small models like Phi2. For AMD ROCM there is no support as per this issue. |
| candle | 🚧 | Latest performance for Candle is not implemented. If you want to see the numbers, please check out which contains the benchmark numbers for Llama 2 7B. |
| ctranslate2 | ⚠️ | ROCM is not supported; however, works are in progress to have this feature on CTranslate2. No support for Mac M1/M2. |
| onnxruntime | ⚠️ | ONNXRuntime in general supports ROCM, but specific to LLMs and ONNXRuntime with HuggingFace Optimum only supports CUDAExecution provider right now. For CPU, it is available but super slow. |
| pytorch lightning | ⚠️ | ROCM is supported but not tested for PyTorch Lightning. |
| pytorch lightning | ⚠️ | Metal is supported in PyTorch Lightning, but for Llama 2 7B Chat or Mistral 7B, it is super slow. |
| AutoGPTQ | ⚠️ | AutoGPTQ is a weight-only quantization algorithm. Activation still remains in either float32 or float16. We used a 4-bit weight quantized model for our benchmarks experiment. |
| Generic | 🚧 | For all the engines which support metal, please check out which contains the benchmark numbers for Llama 2 7B. |
| Deepspeed | ⚠️ | DeepSpeed supports training; however, for inference, we have used DeepSpeed MII. |
Now that we are all familiar with the current scope and the support matrix of the benchmarks repository, let's jump to the analysis that we got from benchmarks.
📐 Crunching the numbers and interesting takeaways
In this section, we are going to visualize some graphs comparing Llama 2 7B chat and Mistral 7B v0.1 instruct performances on different benchmarks. We are also going to point out some key takeaways from qualitative comparisons. Before proceeding further here are some quick notes:
Performance comparison across different precision
Let's jump in to understand the performance benchmarks for Llama 2 7B Chat and Mistral 7B v0.1 instruct. Please note that even though we say both Llama 2 and Mistral are 7B parameter models, Mistral v0.1 is a 7.3 B parameter model, for which we see a very slight increase in memory.
We used this command to run benchmarks across all the inference engines:
./benchmark.sh --repetitions 10 --max_tokens 512 --device cuda --model mistral --prompt 'Write an essay about the transformer model architecture'Let's look into the results for each of the inference engines for different precisions one by one:
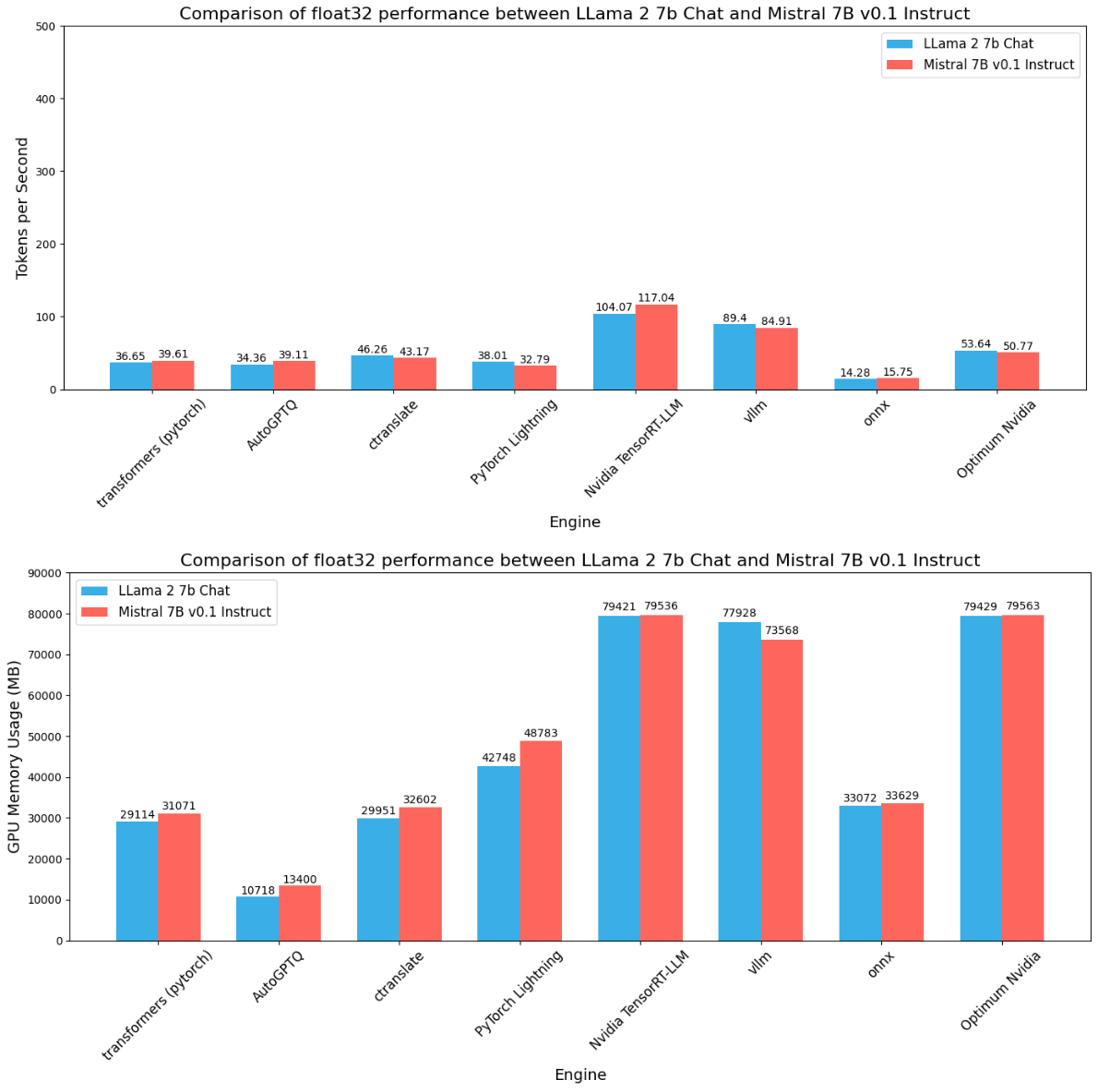
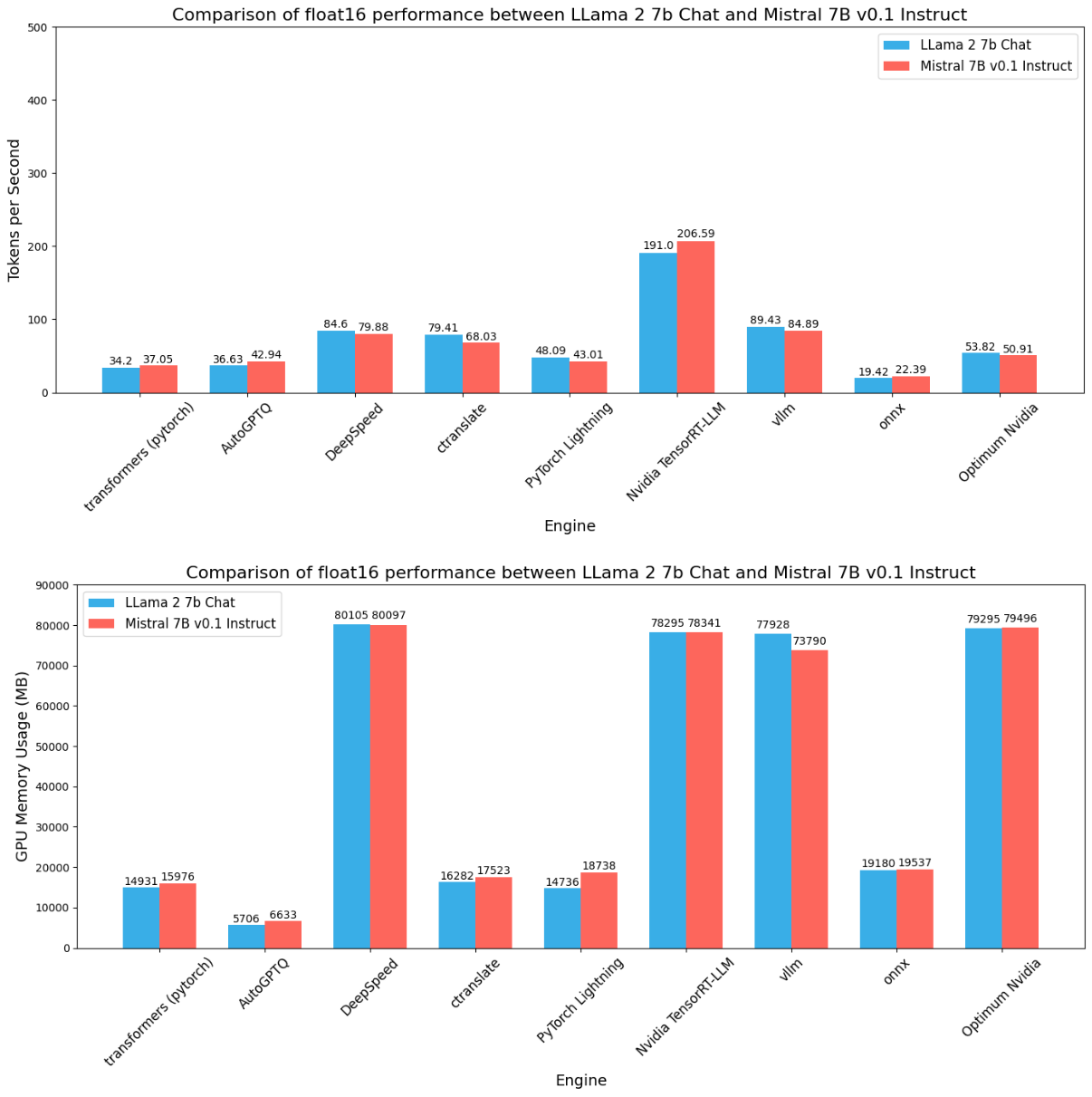
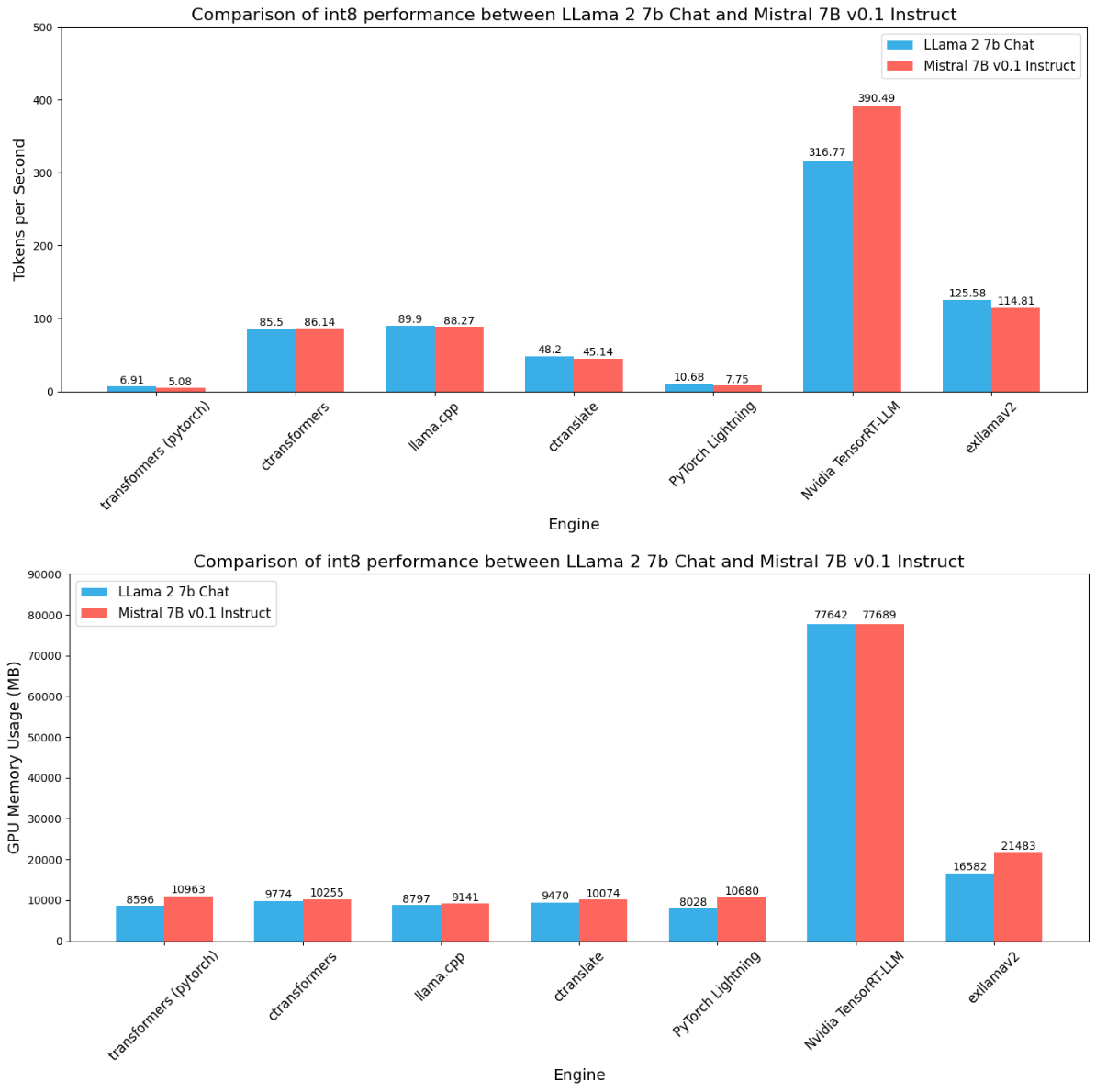
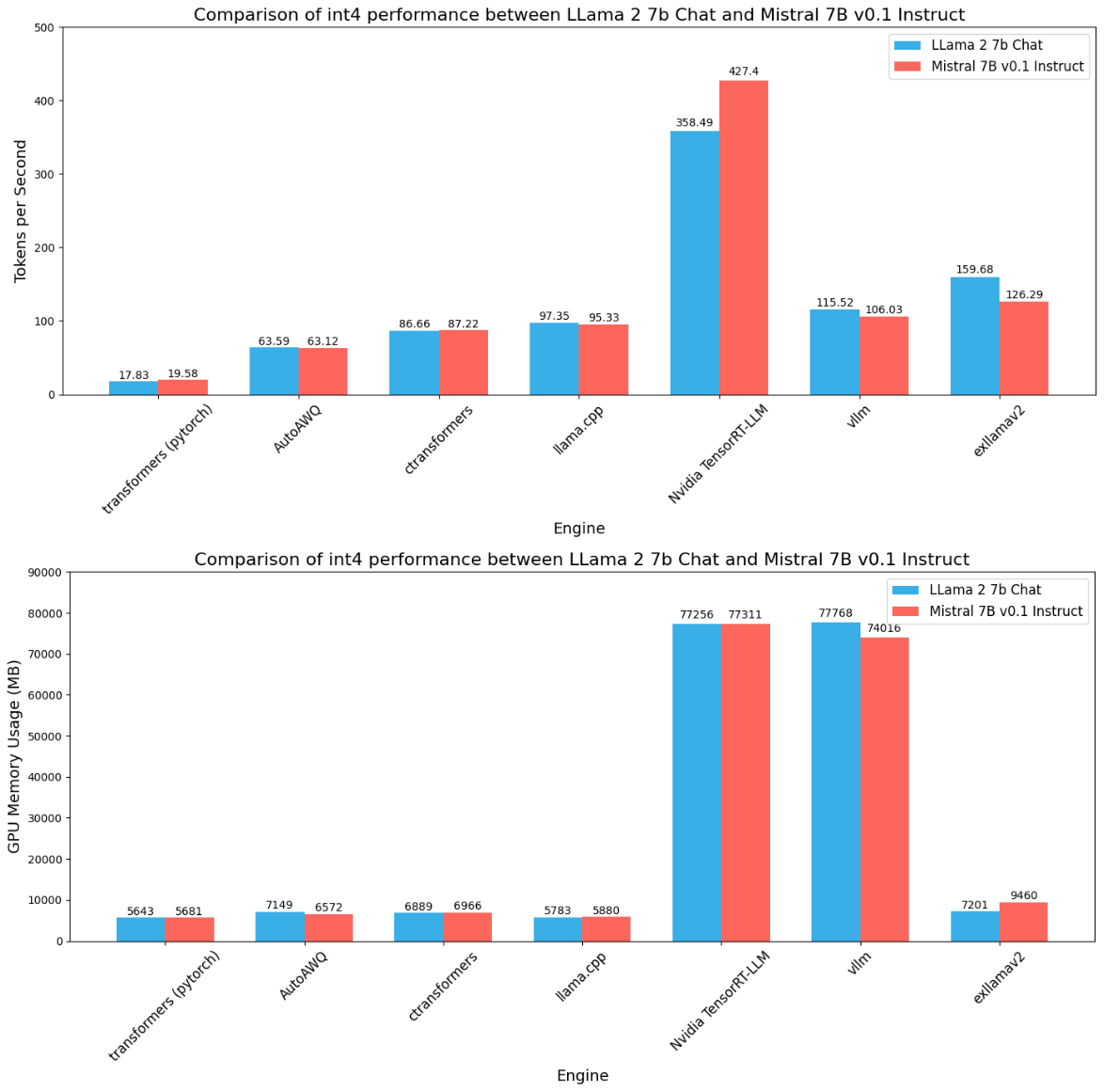
Across all the precisions we see some common patterns:
- There is a direct or linear relationship between precision, throughput, and memory consumption.
- We see Nvidia TensorRT LLM has the highest throughout and also GPU memory consumption. However, with batch size > 1 (example: 128), we can see much more throughput in the order of thousands. You can check those benchmark results.
- AutoGPTQ consumes the least amount of memory and gives good speed. This is becasue it uses mixed precision weights, where weights are only quantized. You can learn more about AutoGPTQ
- Optimum Nvidia gives a good abstraction for TensorRT LLM, but it does not give the same performance as TensorRT LLM does. Also, it does not support int8 or int4 quantization for now.
- Out of everyone, ONNX is the least-performing inference engine. While developing benchmarks for ONNX, we found this common problem of being unable to find GPU. There is no proper documentation on how to resolve this issue particularly regarding documentation on how to use ONNX specifically for LLMs.
- For the quantized version (especially int4), although AutoAWQ consumes the least memory ExLlamaV2 provides a greater edge in speed with a bit more memory consumption.
- Interestingly vLLM consumes a similar amount of memory just like TensorRT LLM but it does not give the same amount of speed, like TensorRT LLM does. DeepSpeed MII on the other hand also shows similar memory consumption but gives average throughput.
- CTranslate2, LlamaCPP, and CTransformers maintain a stable throughput and GPU consumption.
Qualitative comparison across different precision and engines
In each benchmark folder, there is a corresponding readme. Each readme consists of two tables. Sometimes optimizations related to speed or memory consumption might degrade the quality of LLM. For instance, when vLLM was first launched, it became quite popular due to its speed. However, a lot of folks have complained about a certain degradation in generation quality. But thanks to the amazing community, those are solved. The point here is, that when it comes to choosing the right optimization, we need to not only understand the performance (in terms of speed and memory), but also the qualitative perspectives. Here is how we do the comparison:
- Our ground truth is output from models running on float32 precision. We can consider this as our raw weight. We run these models using HuggingFace transformers and store them as our ground truth.
- We take 5 good quality prompts and instruct our LLM to give a very precise answer for those prompts.
- Finally, we empirically compare the results from the model running on certain engines with different precisions with the ground truth, and see if there is any difference in quality. Please note that we set the generation behavior to be as deterministic (temperature set to 0.1) as possible.
Below is an example table of our comparison. This sample is from the AutoAWQ benchmark.

Here are some quick insights that we found when comparing each of the tables across different engines and their supported precisions:
- In all the generations, we saw that Mistral v0.1 generates responses that are shorter in length and more precise compared to Llama 2.
- One of the positive things across all the inference engines is that the quality does not degrade substantially. Sometimes, we see some subtle changes in response for AutoAWQ.
- CTranslate2 unexpectedly shortens the responses, or sometimes generates incomplete text, or generates nothing at all.
- ExLlamav2, on the other hand, prints emojis out of nowhere. It was fun to see the results. However, this does indicate some degradation in the quality of the generation.
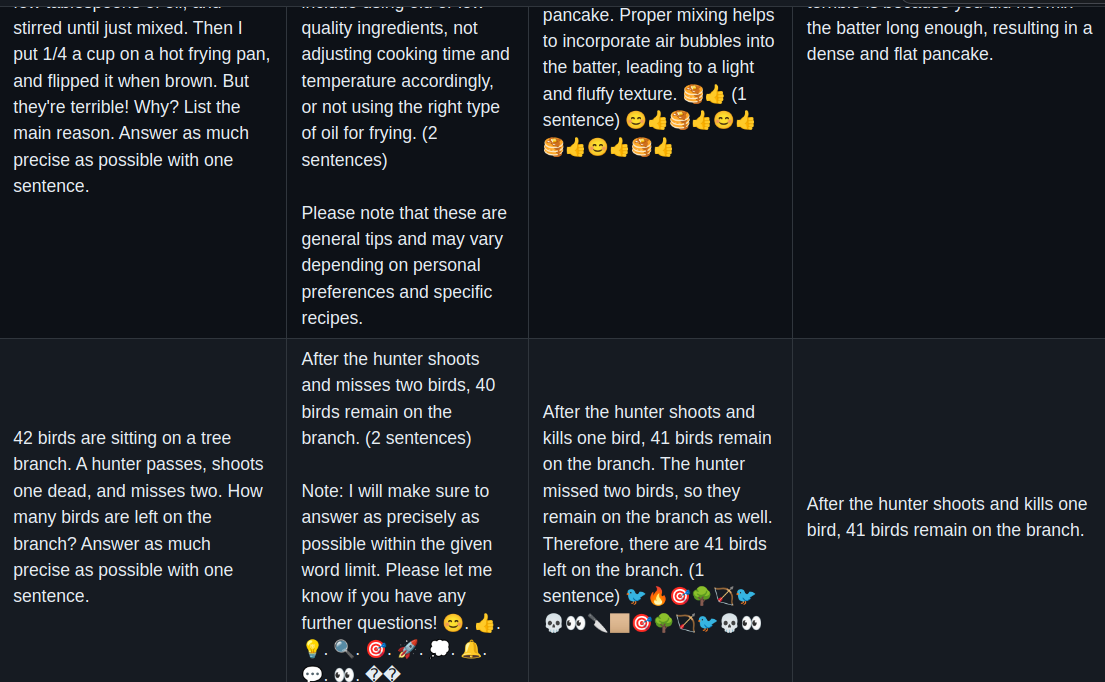
- LlamaCPP is great when it comes to maintaining a good balance between speed, memory usage, and quality of responses.
- Surprisingly, TensorRT LLM covers all the checks without much quality loss, while staying identical across all the precisions.
- vLLM has improved a lot from its initial days and it now provides a stable generation response with lesser degradation in generation quality.
🎊 The Winner
Now, from all the analysis that we have done earlier in terms of the performance of the model and its trade-off with generation quality degradation, it's super clear that Nvidia's TensorRT LLM is the winner here. It provides immense speedup, and the quality remains intact across all the precisions. The only trade-off is the GPU memory usage. However, it can be optimized further by changing some configurations (like max_sequence_length , etc).
We can consider LlamaCPP as our runner-up because it offers significant advantages of running LLMs with lower memory usage, and without compromising much on speed and generation quality. CTrasformers is a nice abstraction and provides interfaces similar to huggingface, which is worth checking out.
🎯 Conclusion
Thank you for taking the time to review our Benchmarks. We can acknowledge that there is still room for improvement in providing as many accurate results as possible. More and more inference engines are coming out like Apple's MLX framework (especially to run LLMs natively on Apple devices), and we are focused on supporting all of them in future versions. In the meantime, please remember to star our benchmarks repo, and give us feedback. If you have any doubts about certain numbers, don't hesitate to let us know and we can double-check and update the numbers if required. Also, feel free to raise any issues or contribute in any way if you are interested. We welcome open-source contributions from the community. Our goal is to establish benchmarks on the single source of truth for decision making regarding which inference engines to choose for running/deploying certain LLMs.