
LLM Datasets and Contamination
Prem AI's post addresses dataset contamination in LLM training, where overlap between training and test sets inflates performance. It explores detection methods, data curation best practices, and ethical concerns around mislabeled or duplicated content.

Large Language Models (LLMs) are in the spotlight, mainly due to their emerging capabilities. Please refer to our previous blog post on Emergent abilities in LLMs for a deeper dive into this topic.
As the old saying goes,
You can't make a silk purse out of a sow's ear.

This observation also holds for LLMs, with a significant portion of their impressive performance attributable to the datasets used for pre-training, fine-tuning, evaluating, and instructing these models.
Data contamination poses a significant challenge in LLM development. Frequently, LLMs undergo evaluation using datasets that contain samples encountered during their training. This results in the models memorizing these examples and demonstrating exceptional performance on corresponding benchmarks. For more info about LLM evaluations, check out our two-part LLM eval series: Part 1 and Part 2.
In this blog post, we explore the usual types of datasets for LLMs and the processes and varieties of data contamination present within these datasets.

🥧 Pre-training Corpora
Pre-training corpora are extensive text collections utilized in the initial training stages of LLMs, offering a vast array of knowledge from unlabeled data across various domains, including the internet, academia, and specific fields like law and medicine. These datasets not only enable the models to understand and generate language but also play a crucial role in enhancing their generalization capabilities and performance across a wide range of natural language processing tasks.
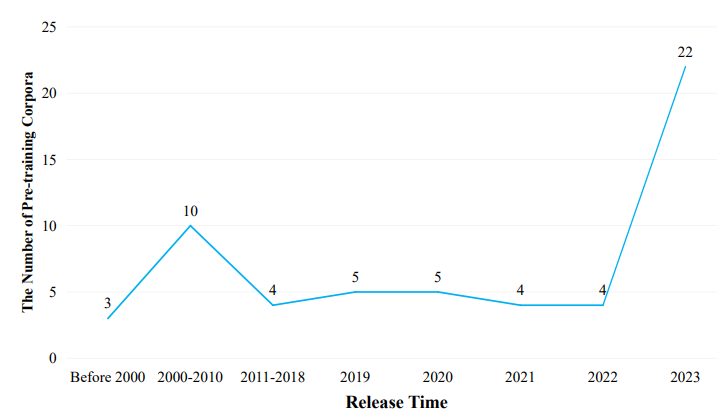
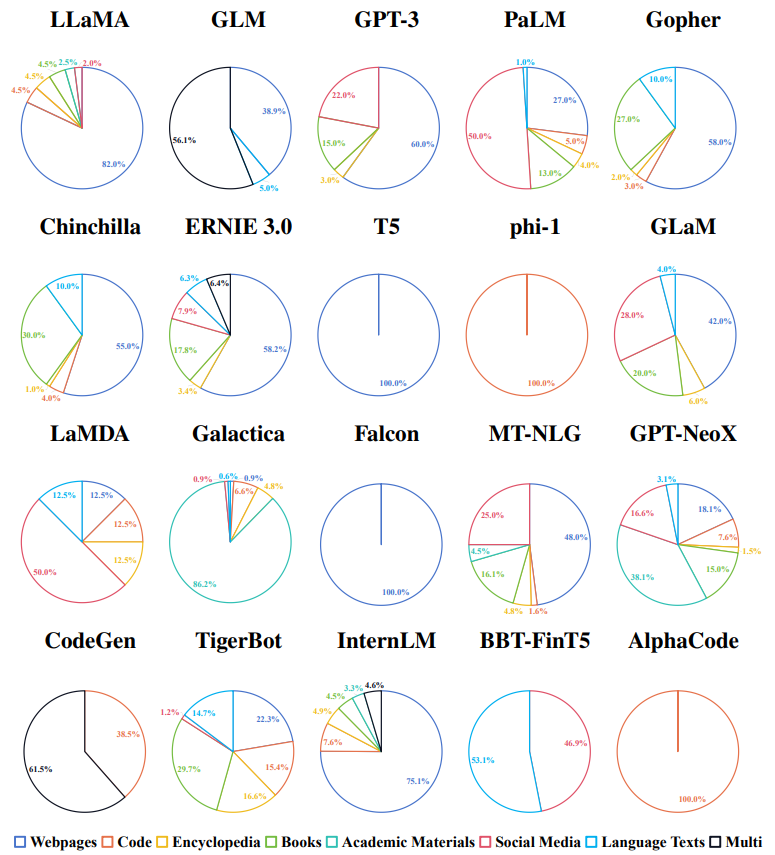
The types of pre-training corpora, along with examples, are:
- General Pre-training Corpora: These encompass a wide range of text from multiple domains to provide a comprehensive language understanding. Examples include:
- Common Crawl: A vast collection of web pages from the internet, capturing diverse topics.
- Wikipedia Dump: Contains encyclopedic entries covering a multitude of subjects, useful for broad knowledge.
- Domain-specific Pre-training Corpora: Tailored to specific fields, these corpora enable models to develop expertise in particular areas. Examples include:
- PubMed Central: A corpus of medical literature for training models on biomedical texts.
- Financial Times Corpus: Contains financial news and reports, ideal for models focusing on the economy and financial markets.
- CaseLaw: A collection of legal documents and case reports for models learning legal language and concepts.
Pre-training data undergoes a comprehensive preprocessing pipeline to enhance quality, ensure standardization, and minimize harmful content. This involves several stages:
- Data Collection: Carefully defining data requirements and sourcing from reliable websites, books, and papers, ensuring legal compliance and privacy protection.
- Data Filtering: Employing model-based and heuristic methods to screen out low-quality or irrelevant content, including harmful material, to improve overall data quality.
- Data Deduplication: Using techniques like TF-IDF, MinHash, and SimHash to eliminate duplicate or highly similar texts, ensuring uniqueness in the dataset.
- Data Standardization: Transforming text to a uniform format, which includes sentence splitting, encoding correction, language detection, and the removal of stop words and spelling correction.
- Data Review: Documenting preprocessing steps and conducting manual reviews to ensure the data meets quality standards, providing feedback for further refinement.
This structured approach ensures that the pre-training data is of high quality and suitable for training robust, effective LLMs.

🧙 Instruction Fine-tuning datasets
Instruction fine-tuning datasets consist of text pairs with "instruction inputs" from humans and "answer outputs" from models, designed to refine models' understanding and execution of diverse tasks like classification, summarization, and more. Constructed through manual efforts, model generation, enhancement of existing datasets, or a mix of these methods, these datasets enable pre-trained models to better follow human instructions, thus improving their functionality and controllability.
They are categorized into general and domain-specific datasets to either broaden models' task performance or provide specialized knowledge in areas such as healthcare. Instruction types are diverse, ranging from reasoning and mathematical problems to creative generation and ethical considerations, aiming to equip models with the ability to tackle a wide array of challenges with accuracy and sensitivity to human values.
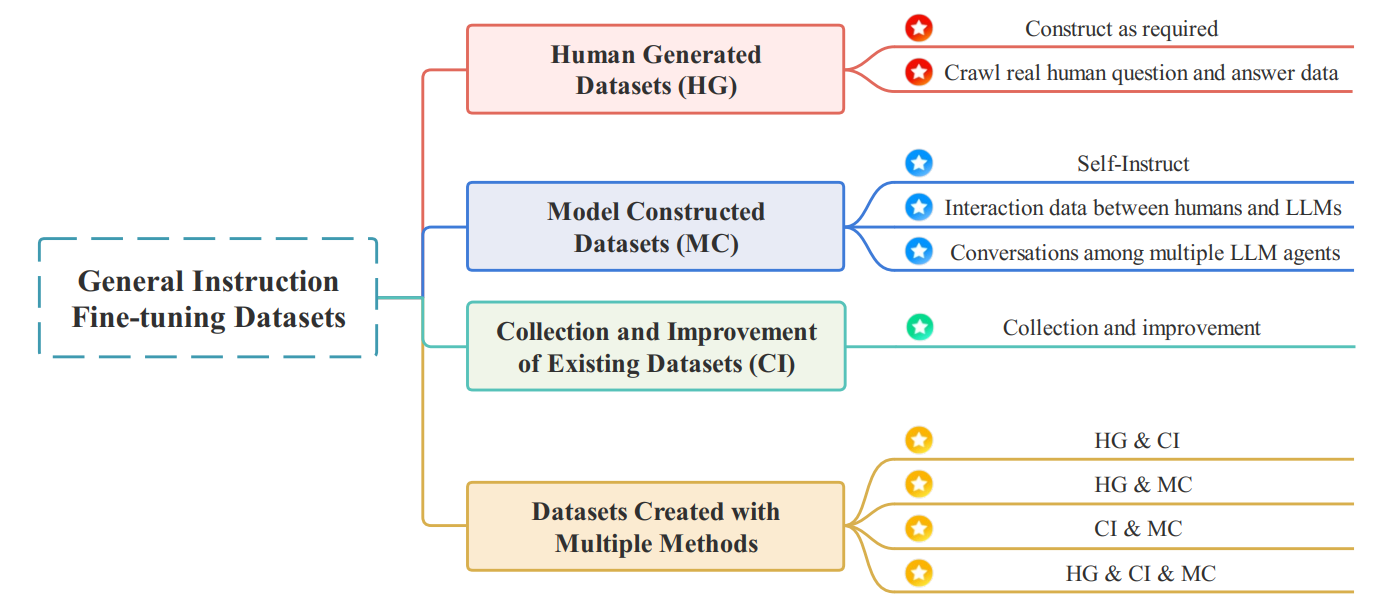
General Instruction Fine-tuning Datasets
- Aim to enhance LLMs' ability to follow a wide range of instructions without domain restrictions.
- Categorized based on construction methods into four main types:
- Human Generated Datasets
- Model Constructed Datasets
- Collection and Improvement of Existing Datasets
- Datasets Created with Multiple Methods
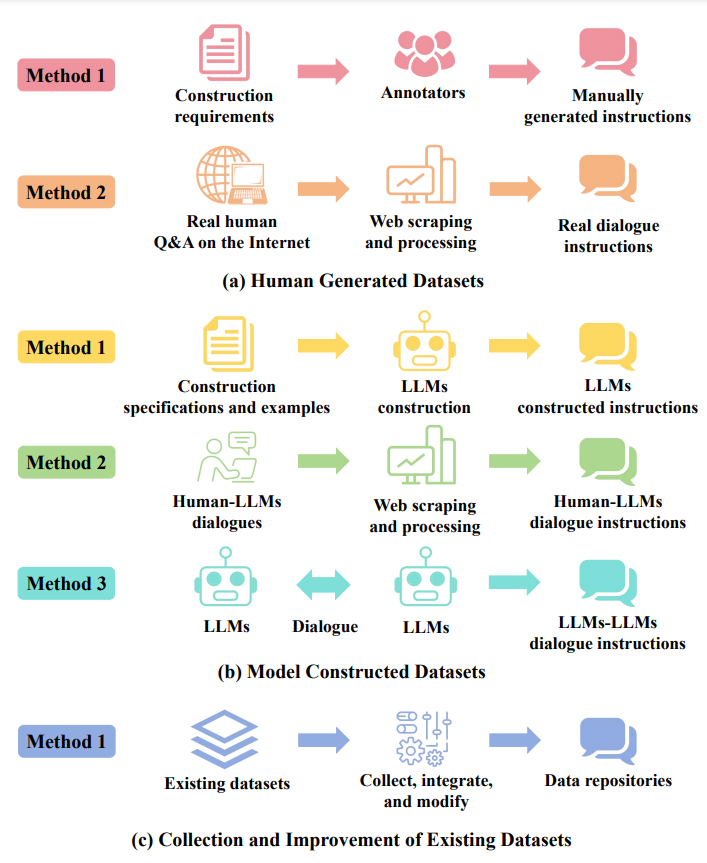
Human Generated Datasets
- Created manually by annotators.
- Examples: Databricks-dolly-15K, OASST1, OL-CC27, The Aya Dataset.
- Advantages: High quality, interpretability, and flexible control.
- Drawbacks: High cost and subjectivity.
Model Constructed Datasets
- Generated using LLMs.
- Examples: Self-Instruct dataset, Alpaca data, BELLE Generated Chat, RedGPT-Dataset-V1-CN.
- Advantages: Abundant data and cost-effectiveness.
- Drawbacks: Variable quality and need for post-processing.
Collection and Improvement of Existing Datasets
- Integrating and modifying open-source datasets.
- Examples: CrossFit, DialogStudio, Dynosaur, Flan-mini.
- Advantages: Diversity and large scale.
- Drawbacks: Need for quality and format standardization.
Datasets Created with Multiple Methods
- Combining human generation, model construction, and dataset improvement.
- Examples: Firefly, InstructGPT-sft, Alpaca GPT4 data, COIG.
🎲 Preference datasets
Preference datasets contain instruction-response pairs evaluated for their alignment with human preferences, focusing on utility, honesty, and safety. These datasets, featuring feedback through voting, sorting, and scoring, guide LLMs in producing responses that closely match human expectations. They are used during the model alignment phase to refine outputs, ensuring they are instructive, truthful, and safe. Methods like Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) utilize these datasets for model optimization. Additionally, training reward models with preference data and applying Proximal Policy Optimization (PPO) further fine-tunes LLMs to better understand and adhere to human preferences.
Preference Evaluation Methods
Preference datasets evaluate the desirability of multiple responses to the same input using various methods, such as voting, sorting, scoring, and other techniques. These methods aim to discern human or model preferences across a range of responses within a specific task or context. Both humans and high-quality LLMs can conduct evaluations, with each having its advantages and challenges. Human feedback, while closely aligned with real-world scenarios, may introduce subjectivity and inconsistencies. Conversely, model feedback leverages extensive knowledge and saves time but might incorporate biases. A combined approach utilizing different feedback sources tends to yield more balanced and comprehensive results.
Preference Evaluation Methods:
- Vote: Choosing the preferred option(s) from a set of answers. Its simplicity facilitates easy collection and group opinion reflection, though it lacks detail.
- Sort: Arranging responses in a predetermined order based on specific criteria. This method offers detailed preference order information but requires standardization.
- Example: OASST1 pairwise rlhf reward.
- Score: Assigning numerical values to responses. Scoring delivers a nuanced understanding of preferences but demands uniform criteria and awareness of subjectivity.
- Other: Some datasets utilize unique evaluation techniques to align model outputs with specific criteria or preferences.
- Examples: Medical-rlhf, PRM800K.
🔍 Evaluation datasets
Evaluation datasets serve as critical tools for measuring the performance of LLMs across a variety of tasks. These datasets are divided into distinct domains, each focusing on a specific aspect of LLM capabilities, ranging from general language understanding to specialized knowledge in fields like law, medicine, and mathematics. For instance, general domain evaluations test the versatility of LLMs across diverse categories and domains, assessing their ability to understand and follow instructions.
Specialized domain evaluations delve into LLMs' proficiency in specific areas by using domain-relevant tasks and exam questions. This includes evaluating LLMs on legal reasoning, medical diagnostics, and their ability to solve complex mathematical problems. Natural Language Understanding (NLU) and reasoning datasets assess LLMs' grasp of language semantics, grammar, and their logical reasoning capabilities.
Furthermore, knowledge and long text evaluation domains focus on LLMs' capacity to retain, analyze, and apply information, as well as their performance in processing extensive texts. This broad spectrum of evaluation domains ensures a comprehensive assessment of LLMs, highlighting their strengths and pinpointing areas for improvement. Through these datasets, developers can identify specific capabilities that need enhancement, guiding future research and optimization efforts.
🐉 Traditional NLP datasets
Traditional NLP Datasets are designed for natural language processing tasks, emphasizing text classification, information extraction, text summarization, and more. These datasets are used for training, optimizing, and testing NLP models, which are applied in a variety of text processing tasks.
- Question Answering datasets evaluate models on their ability to use knowledge and reasoning to answer queries. This includes:
- Reading Comprehension, where models answer questions based on provided texts, with datasets like SQuAD and CNN-DM. Knowledge QA, testing models' world knowledge without reference texts, using datasets such as ARC and CommonsenseQA. Reasoning QA, focusing on models' logical and multi-step inference abilities, with datasets like HellaSwag and Social IQa.
- Recognizing Textual Entailment (RTE) involves assessing if information in one text segment can logically be inferred from another, with datasets including RTE and ANLI.
- Math datasets challenge models with tasks ranging from basic calculations to advanced mathematical reasoning, exemplified by GSM8K and MATH datasets.
- Coreference Resolution tasks, found in datasets like WiC and WSC, require identifying referential relationships within texts.
- Sentiment Analysis involves categorizing texts based on emotional tones, with datasets like SST-2 and IMDB.
- Semantic Matching tasks assess the semantic similarity between text sequences, using datasets such as MRPC and QQP.
- Text Generation tasks challenge models to create coherent text based on specific conditions or structured data, with examples including CommonGen and DART.
- Text Translation tasks involve translating text between languages, with notable datasets like WMT and IWSLT 2017.
- Text Summarization requires generating concise summaries from longer texts, using datasets such as CNN-DM and XSum.
- Text Classification involves assigning texts to predefined categories, with datasets like AGNEWS and TNEWS.
- Text Quality Evaluation focuses on identifying and correcting grammatical or language usage errors, with datasets like CoLA and CSCDIME.
- Text-to-Code tasks test models' ability to convert natural language descriptions into executable code, exemplified by MBPP and Spider datasets.
- Named Entity Recognition (NER) identifies and categorizes named entities within text, using datasets like CoNLL2003 and OntoNotes 5.0.
- Relation Extraction (RE) tasks identify relationships between entities within text, with examples including Dialogue RE and DocRED.
- Multitask datasets like CSL and QED provide text samples for multiple NLP tasks, showcasing the versatility of textual data in diverse challenges.
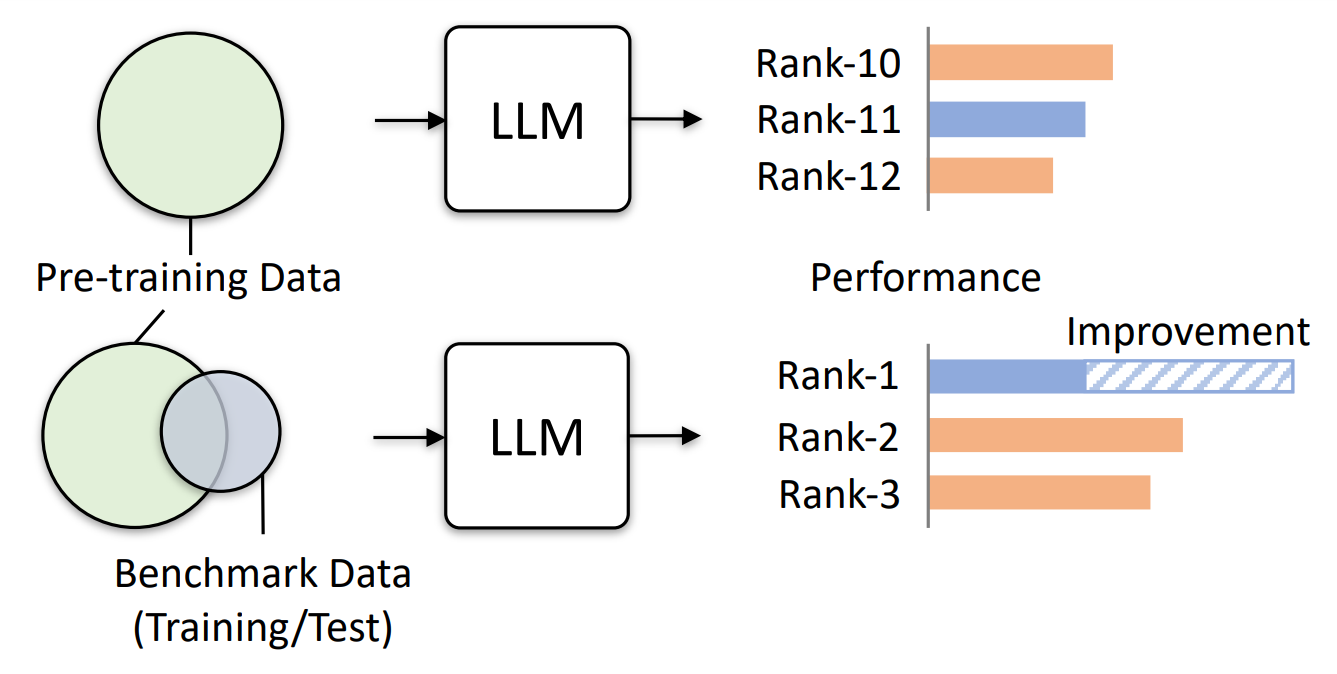
☢️ Data contamination
LLM data contamination refers to the unintentional inclusion of test sets from natural language processing (NLP) benchmarks within the training data of LLMs. This overlap can skew performance evaluations, as models may inadvertently be tested on data they were trained on, leading to an overestimation of their capabilities.
This contamination typically occurs because LLMs are trained on massive datasets compiled by scraping content from the web. These datasets often contain documents or texts that are part of or similar to the benchmarks used for evaluating the models later. For instance, if an LLM is trained on a dataset that includes the exact questions and answers from a popular NLP benchmark, it might perform exceptionally well on that benchmark not because it has generalized well from the training data but because it has seen the test questions during training.
Evidence
Detail on evidence of data contamination:
- Extensive Leakage of Benchmark Data: The analysis conducted in this research found that approximately 4.7 million samples from 263 different benchmarks were exposed to GPT-3.5 and GPT-4 through the web interface. This large-scale exposure occurred because many researchers and users interacted with these models using benchmark datasets for evaluating model performance. As these interactions were not filtered out from the training data of subsequent model iterations, it means that GPT-3.5 and GPT-4 could have been indirectly trained on a significant portion of the very datasets used to evaluate them. This situation presents a clear case of data contamination, as the models might perform well not solely on their general language understanding capabilities but because they have "seen" the test data during their training phases.
- Usage of Labeled Examples in Queries: Another concrete evidence of data contamination comes from the instances where researchers used labeled examples when interacting with ChatGPT. This approach is problematic because it directly feeds the model information about the expected output for a given input. For example, when researchers use a few-shot learning approach by providing the model with a prompt that includes several examples of input-output pairs (where the outputs are the correct answers or desired responses), and then ask the model to produce an output for a new, similar input. If these input-output pairs come from the test sets or benchmarks, the model is being directly exposed to the evaluation data along with the answers. This not only contaminates the model with the test data but also with the correct answers to the evaluation tasks, thereby artificially inflating the model's performance metrics.
These instances of data contamination underscore the challenges in ensuring that LLMs are evaluated in a fair and unbiased manner, highlighting the need for rigorous evaluation protocols that prevent any form of data leakage.
🔎 Evaluation
Contamination is evaluated through several methodologies that aim to detect, quantify, and understand the extent to which training data for LLMs includes information from test sets or evaluation benchmarks. These methodologies include:
- Direct Analysis of Training Data: This involves examining the datasets used for training LLMs to identify any direct overlaps with known evaluation benchmarks or test sets. This can be done through string matching, hash comparisons, or other forms of direct content comparison.
- Memorization Detection Techniques: Researchers use techniques to assess the extent to which LLMs have memorized specific pieces of information from their training data. This can involve prompting models with partial inputs from the benchmarks and observing whether the outputs closely match the expected responses, indicating potential contamination.
- Auditing Tools: The development and use of specialized software tools designed to audit the contents of an LLM's training data against a database of benchmark datasets. Tools like ROOTS or Data Portraits allow for large-scale analysis and detection of overlaps between training corpora and benchmark data.
- Reverse Engineering: Attempting to reconstruct elements of the training data by analyzing the model's outputs. This approach exploits the fact that LLMs, especially those with high memorization capacity, can reproduce snippets of text that are very similar or identical to those in their training data when given specific prompts.
- Statistical Analysis: Applying statistical methods to compare the distribution of words, phrases, or syntactic structures between the model's training data and the evaluation benchmarks. Significant similarities might indicate contamination, especially if these elements are unique to the benchmarks.
- Benchmark Data Overlap Measures: For open models where training data is accessible, measuring the degree of overlap with evaluation benchmarks can be straightforward. This involves calculating the percentage of the benchmark present in the training dataset.
- Investigating Model Behavior: Analyzing the model's performance across different datasets and looking for anomalies where performance is significantly better on specific benchmarks might suggest prior exposure to those benchmarks during training.
- Community Efforts: Collaborating with the broader research community to document and share findings related to data contamination cases. This includes establishing registries of known contamination instances and sharing methodologies for detection and mitigation.
🧹 Mitigation
Reducing, removing, or mitigating data contamination in LLMs involves a combination of short-term and long-term strategies aimed at improving the quality and integrity of machine learning research. These strategies focus on preventing the inclusion of evaluation benchmark data in training datasets and ensuring that the evaluation of models is based on truly unseen data.
Short-term Strategies
- Data Auditing and Cleaning: Immediately implement rigorous data auditing processes to identify and remove any known benchmark datasets or closely related data from training corpora. This includes using string matching, hash comparison, and manual review to ensure training data does not contain elements of test sets.
- Transparent Documentation: Require transparent documentation of data sources, preprocessing steps, and data cleaning methodologies used in the training of LLMs. This helps identify potential contamination sources and facilitates replication and verification by independent researchers.
- Use of Cleaned Datasets: Adopt cleaned and verified datasets that have been specifically curated to remove any overlap with known benchmarks. Researchers and organizations can collaborate to create and maintain these cleaned datasets.
- Benchmark Redesign: Redesign benchmarks and evaluation protocols to include dynamic elements or periodically updated test sets, making it more difficult for models to be inadvertently trained on test data.
Long-term Strategies
- Developing Robust Detection Tools: Invest in the development of more sophisticated tools and technologies for detecting data contamination. This could involve machine learning models trained to identify overlaps between training data and benchmarks, as well as more advanced data auditing software.
- Community-Wide Data Governance: Establish community-wide standards and protocols for data collection, sharing, and usage. This includes creating repositories of safe-to-use training data and benchmarks, along with mechanisms for tracking and reporting contamination incidents.
- Differential Privacy and Secure Multi-party Computation: Explore the adoption of differential privacy techniques and secure multi-party computation in the training process. These techniques can help minimize the risk of data contamination by ensuring that individual data points do not unduly influence the trained model.
- Continuous Education and Awareness: Foster ongoing education and awareness efforts within the research community about the risks of data contamination and the importance of clean training practices. This can include workshops, tutorials, and shared resources on best practices for data handling.
- Incentivizing Clean Research Practices: Encourage journals, conferences, and funding bodies to require declarations regarding data contamination and to prioritize the publication and support of research that adheres to best practices in data cleanliness.
- Long-term Benchmark Development: Invest in the development of more sophisticated and robust benchmarks that are resistant to contamination, such as those that require deeper understanding and generalization, or those that leverage real-time data.
By implementing these short-term and long-term strategies, the research community can mitigate the impact of data contamination on the development and evaluation of LLMs, ensuring that progress in the field is based on accurate and reliable assessments of model capabilities.
📜 References
- Datasets for Large Language Models: A Comprehensive Survey
- Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs
- NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
- Investigating Data Contamination for Pre-training Language Models
- LM Contamination Index
- Don’t Make Your LLM an Evaluation Benchmark Cheater