
PremSQL: Towards end-to-end Local First Text to SQL pipelines
PremSQL is a local-first, open-source Text-to-SQL solution that ensures data privacy and control by avoiding third-party models. With support for small language models, PremSQL simplifies natural language querying and provides autonomous, AI-driven data analysis.


Generative AI has become an integral part of the overall technology landscape. While generative AI solutions have typically depended on third-party, closed-source providers, this often comes at the cost of data privacy and control. One of the most valuable and exciting use cases of AI is Natural Language to SQL (NL2SQL), which enables autonomous AI-driven data analysis without the steep learning curve. With PremSQL, we are introducing our new open-source package for developing fully local, end-to-end Text to SQL pipelines.
Currently, several solutions provide text-to-SQL capabilities or LLM-powered data analysis. Companies like Pinterest and Swiggy have been making these internally. However, most of them are not local first. This is great when the data that drives these models is relatively sensitive. However, when it comes to sensitive and private data, exposing it to third-party closed-source model providers can be a significant security breach and break compliance.
 premAI-io
premAI-io
So today, we are excited to release PremSQL. It is a fully open-source, local-first library designed to help developers build and deploy text-to-SQL solutions with small language models. Whether you want a quick solution to query your databases or need a fully customized pipeline, PremSQL empowers you with the right tools while keeping your data secure and private. Here are some quick use cases which can be done using PremSQL.
- Database Q&A
- RAG with database integration
- SQL autocompletion
- AI-powered, self-hosted data analysis
- Autonomous agentic pipelines with database access
And many more. PremSQL's main objective is to provide all the necessary tools for building your text-to-SQL use case so you can focus on your databases, work on integrating into your existing backend, etc.
You might wonder how it differs from LangChain / Llama-Index or DSPy. While these libraries excel in building general AI workflows, they often have a steep learning curve for customization. PremSQL simplifies this, providing complete control over your data and a smooth integration with our simplified yet customizable APIs. Bonus point! You can also integrate this with any of your existing pipelines written on either of these libraries.
In this blog, we will learn about this library's core features, what it currently offers, and what is in our future roadmap. Without further ado, let's get started.
🧩 The problem
Text-to-SQL bridges the gap between complex database schemas and natural language, making database querying accessible to non-experts. According to the Stackoverflow 2023 survey, 51.52% of developers use SQL, but many struggle with complex queries. PremSQL addresses these challenges by offering a comprehensive suite of tools that make NL2SQL simple, secure, and powerful—without relying on third-party closed-source models that can jeopardize data privacy.
 Anindyadeep Sannigrahi
Anindyadeep Sannigrahi
To get started with PremSQL, install our official package:
pip install -U premsql🦾 PremSQL Architecture
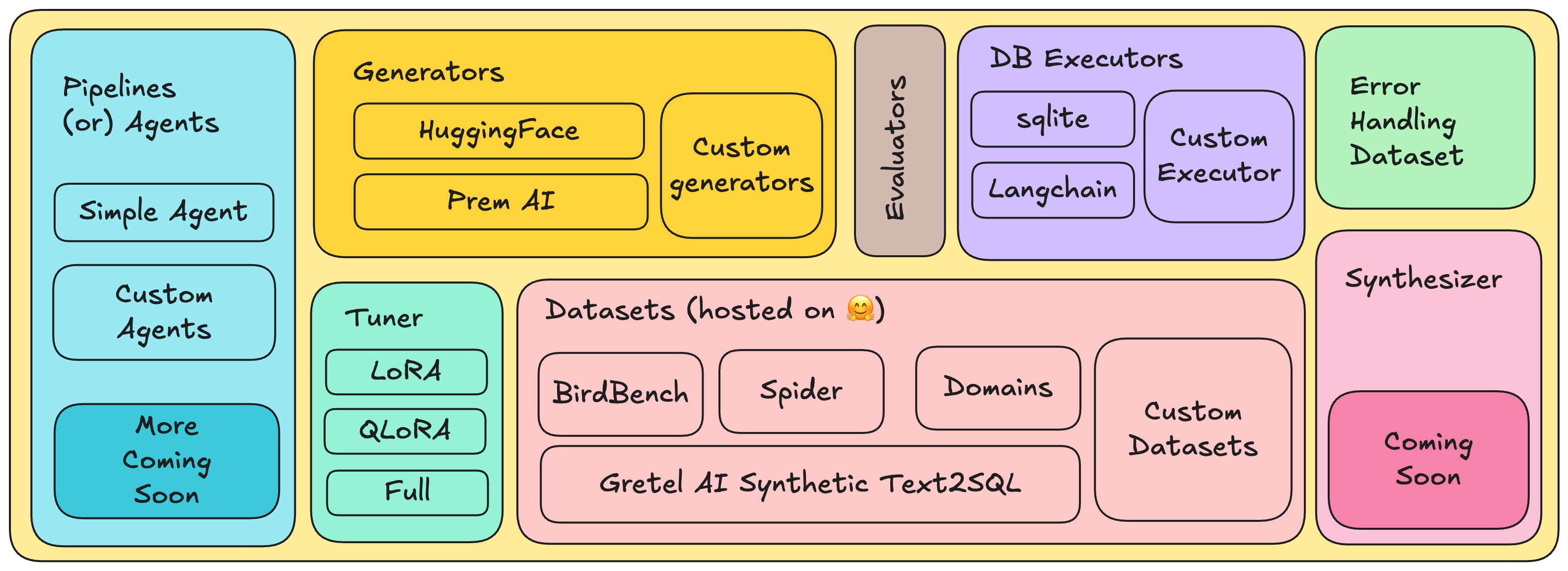
This problem of text-to-SQL can be divided into some reusable independent components. For making fully local autonomous solutions for Text to SQL, PremSQL offers the following components (shown above). Let's discuss each of them in detail.

💽 Datasets
It provides good training and validation datasets for fine-tuning and evaluation models for this task. Text-to-SQL is a complex task. The data here is not simple text. It should have the following things, at the very least:
- Instruction: A proper instruction that tells what to do and what not to do.
- Schema: All the schemas of the tables in the database. Our modules connect with the database and automatically provide all the schemas of all the available tables in a prompt-like format.
- Few-shot examples: Few-shot prompting always helps for more reliable generations. So, our module automatically provides few-shot examples when creating datasets for text-to-SQL. It also provides interfaces to provide custom short question-and-answer pairs during the inference process.
- Additional Knowledge: Sometimes, it is important to provide additional knowledge about the database and the tables. This includes contextual and semantic information about the overall database, tables, columns, etc.
Last but not least, an area where the question is appended and asked. Here is what a standard prompt looks like in premsql.
BASE_TEXT2SQL_PROMPT = """
# Follow these instruction:
You will be given schemas of tables of a database. Your job is to write correct
error free SQL query based on the question asked. Please make sure:
1. Do not add ``` at start / end of the query. It should be a single line query in a single line (string format)
2. Make sure the column names are correct and exists in the table
3. For column names which has a space with it, make sure you have put `` in that column name
4. Think step by step and always check schema and question and the column names before writing the
query.
# Database and Table Schema:
{schemas}
{additional_knowledge}
# Here are some Examples on how to generate SQL statements and use column names:
{few_shot_examples}
# Question: {question}
# SQL:
"""
Here is a glimpse of what the usage of PremSQL datasets looks like:
from premsql.datasets import Text2SQLDataset
from premsql.utils import print_data
# Load the BirdBench dataset
bird_dataset = Text2SQLDataset(
dataset_name='bird', split="train", force_download=False,
dataset_folder="path/to/store/the/dataset"
)
PremSQL provides most popular open source datasets for Text to SQL readily available and pre-processed. Currently the following datasets are supported:
Also, PremSQL datasets provide interfaces you can extend to make custom datasets for your private databases. This can only be done when an annotated raw dataset exists and follows a standardization provided by premsql. More on that below. You can learn more about datasets in our documentation:

🛠️ Executors
An executor executes the generated SQL queries against the database and fetches the results. It is a crucial component in the Text-to-SQL pipeline, as it ensures that the generated SQL queries are valid and return the expected results. PremSQL supports a native executor for SQLite databases and also supports LangChain's SQLDatabase as an executor. Here is an example:
from premsql.executors import SQLiteExecutor
# Instantiate the executor
executor = SQLiteExecutor()
# Set a sample dataset path
db_path = "./data/db/california_schools.sqlite"
sql = 'SELECT movie_title FROM movies WHERE movie_release_year = 1945 ORDER BY movie_popularity DESC LIMIT 1'
# execute the SQL
result = executor.execute_sql(
sql=sql,
dsn_or_db_path=db_path
)
print(result)Learn more executors in our documentation
⚖️ Evaluators
PremSQL Text2SQLEvaluator It lets you evaluate your models/pipelines using the executors w.r.t. a gold dataset. Our evaluators support the following metrics as of now:
- Execution Accuracy (EX)
- Valid Efficiency Score (VES)
You can learn more about these metrics in our previous blog. We have provided an in-depth explanation of how evaluation for Text to SQL task works and how it can be achieved using the PremSQL library.
Anindyadeep Sannigrahi
Ultimately, you can evaluate any text-to-SQL model/pipeline on any database if you make an executor of it. Here is a quick glimpse of how to use an executor and use that executor for evaluating models.
from premsql.executors import SQLiteExecutor
from premsql.evaluator import Text2SQLEvaluator
# Define the executor
executor = SQLiteExecutor()
# Define the evaluator
evaluator = Text2SQLEvaluator(
executor=executor,
experiment_path=generator.experiment_path
)
# Now evaluate the models
results = evaluator.execute(
metric_name="accuracy",
model_responses=response,
filter_by="db_id",
meta_time_out=10
)
print(results)You might have seen that PremSQL Datasets allows for the filtering of datasets by some parameters. For example, let's say your dataset has different DBs (characterized by db_id or have different difficulty levels). Similarly, you can filter your execution results on similar filters if those results come from the same dataset. In our above example, we filtered by db_id and doing this, let us plot these nice graphs. This becomes quite helpful in analysing model responses to different types of questions and helps in better empirical evaluations.
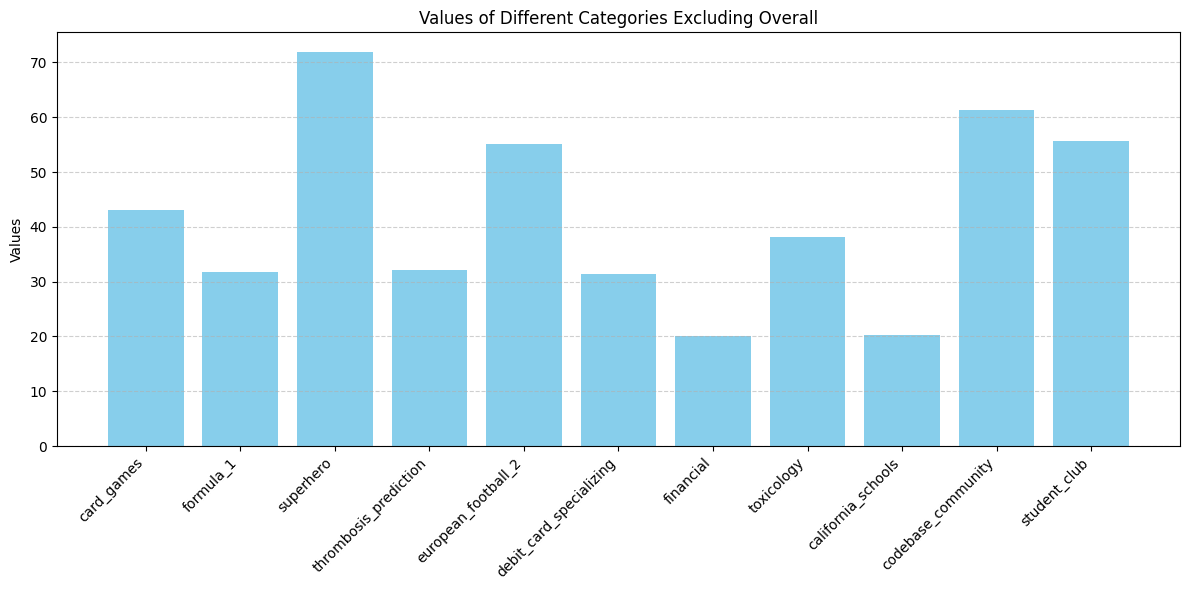
Last but not least, you can write your custom executor. All you need to do is write the execution logic. For example, if you want to make a custom executor for the Postgres database, you can use Psycopg2 to connect the DB / DSN and write your execution logic. It will be compatible with all the other components of PremSQL. You can learn more about them in the executor sections of our documentation.
🍀 Generators
PremSQL generators are responsible for converting natural language questions into SQL queries. Think of these as modular inference APIs specific to text-to-SQL. You can integrate various third-party APIs and models and also write custom pipelines.
PremSQL provides two generations of decoding methods. One is simple decoding, which takes the prompt and gives the result. The second one is execution-guided decoding, which generates the output from the input prompt and executes the SQL output. If this execution does not succeed, then it will retry. But now, internally, it uses an error prompt (more on that below) to self-correct itself. This happens till it gives out a correct SQL or runs out of max trials (max is set to 5 by default). This is how Execution decoding looks like:
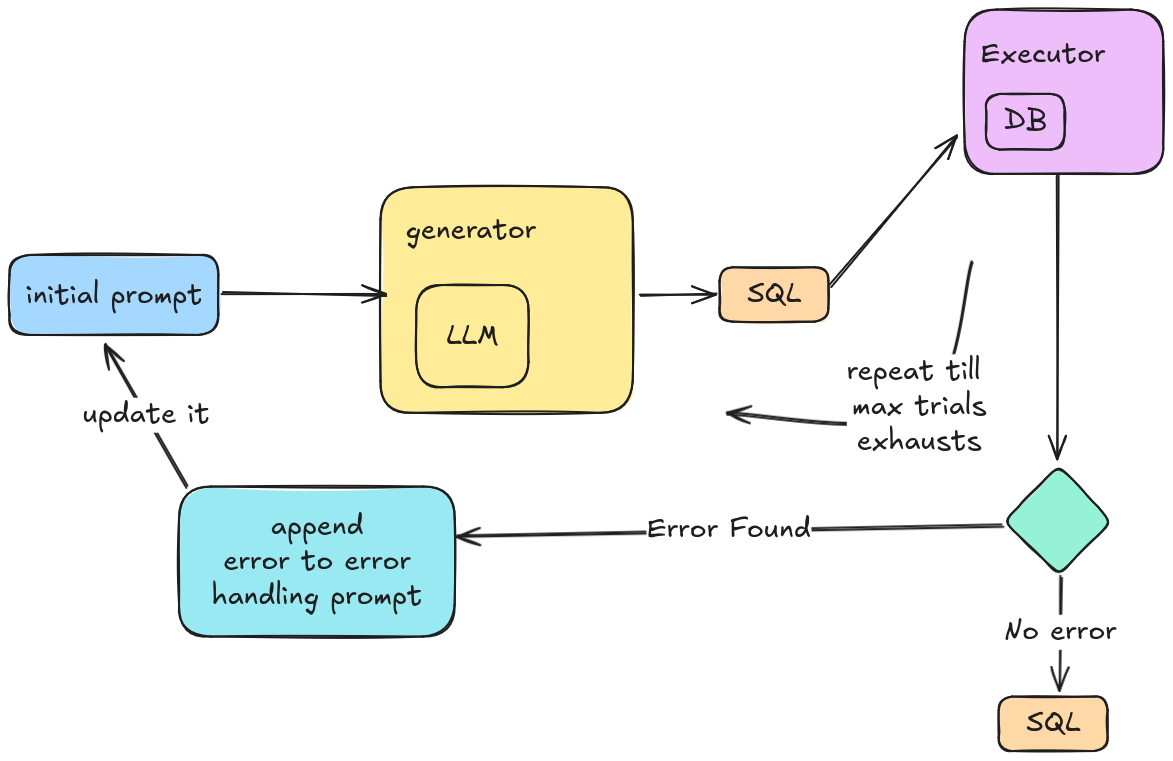
Getting started with generators is very simple:
from premsql.generators import Text2SQLGeneratorHF
from premsql.datasets import Text2SQLDataset
# Define a dataset
dataset = bird_dataset = Text2SQLDataset(
dataset_name='bird', split="train", force_download=False,
dataset_folder="/path/to/dataset"
).setup_dataset(num_rows=10, num_fewshot=3)
# Define a generator
generator = Text2SQLGeneratorHF(
model_or_name_or_path="premai-io/prem-1B-SQL",
experiment_name="test_generators",
device="cuda:0",
type="test"
)
# Generate on the full dataset
responses = generator.generate_and_save_results(
dataset=bird_dataset,
temperature=0.1,
max_new_tokens=256
)
print(responses)By default, we support PremAI SDK, HuggingFace models and Open AI. Similar to the above three, you can create your custom generator. To learn more, visit the generators section in the PremSQL documentation.
🧐 Error Handling
Error-handling prompts are crucial for refining model performance, especially in complex tasks like text-to-SQL generation. The prompts help the model learn how to handle errors by providing additional context and guidance based on past mistakes. By training on these prompts, the model can self-correct during inference, improving the quality of its output. Here is what our default error correction prompt looks like:
ERROR_HANDLING_PROMPT = """
{existing_prompt}
# Generated SQL: {sql}
## Error Message
{error_msg}
Carefully review the original question and error message, then rewrite the SQL query to address the identified issues.
Ensure your corrected query uses correct column names,
follows proper SQL syntax, and accurately answers the original question
without introducing new errors.
# SQL:
"""To generate a self-correction or error correction dataset, we need the current generation of the model, along with the question and prompt that were used for the generation. This module also helps in data augmentation, where we not only increase the overall number of data points in the dataset but also introduce the model's self-correction capability when it is fine-tuned with this data.
In summary, this is the overall workflow of the error-handling dataset:
- You start with an existing training dataset
- You run an evaluation on that training dataset using an un-trained model.
- You gather the data and pass it to the error-handling prompt
- Finally, you save the results ready to be used for fine-tuning.
Here is a glimpse of creating an error-handling dataset using PremSQL.
from premsql.datasets.error_dataset import ErrorDatasetGenerator
from premsql.generators.huggingface import Text2SQLGeneratorHF
from premsql.executors.from_langchain import ExecutorUsingLangChain
from premsql.datasets import BirdDataset
generator = Text2SQLGeneratorHF(
model_or_name_or_path="premai-io/prem-1B-SQL",
experiment_name="testing_error_gen",
type="train", # do not type: 'test' since this will be used during training
device="cuda:0"
)
executor = ExecutorUsingLangChain()
bird_train = BirdDataset(
split="train",
dataset_folder="/path/to/dataset"
).setup_dataset(num_rows=10)
error_dataset_gen = ErrorDatasetGenerator(generator=generator, executor=executor)
error_dataset = error_dataset_gen.generate_and_save(
datasets=bird_train,
force=True
)
So, suppose your training datasets had 9K data points. Now, with the error counterparts, you will have ~ 2x datapoints ready for fine-tuning. To learn more about error-handling datasets, you can check out our documentation.
🧪 Tuner
PremSQL fine-tuner is a simple wrapper written on top of HuggingFace Transformers. It lets you fine-tune models for text-to-SQL tasks. Currently, it supports LoRA, QLoRA, and Full Fine-Tuning. You can even use your fine-tuning pipelines to train your models because our datasets are compatible with Huggingface. Text-to-SQL is an accuracy-first task. This means that the task is not only to generate "SQL-like " texts but also to generate correct executable SQL queries. So, using validation metrics with simple text matching is incorrect.
So, we have created a custom HuggingFace Evaluation callback method that uses PremSQL Evaluators to evaluate the model checkpoints on actual benchmark datasets and returns useful metrics like Execution Accuracy and VES. To learn more about Fine-tuning.
🚰 Pipelines
Pipelines are the most interesting part of PremSQL. You can think about pipelines as the component that uses the other building blocks to build end-to-end solutions for Text-to-SQL. You might wonder what the difference is between pipelines and generators. Generators require much input information, including the prompts, DB connection URL, etc., and only expect you to return SQL statements. In pipelines, you first connect with your database during the initialization of the pipeline. After this, your input only becomes the user's question.
The output of pipelines can be anything. It can be a SQL query, an output (which came from DB execution by generated SQL query), a chart, a summarized data analysis, etc. So pipelines use the generators and executors components under the hood to drive the generations and execution.
So, to summarize, PremSQL pipelines act as a final entry point to interface between your Databases and the user queries. Currently, PremSQL has a simple pipeline that connects to a database and gives out Pandas data frames based on the questions asked. Here is what our simple pipeline looks like:
from premsql.pipelines import SimpleText2SQLAgent
from premsql.generators import Text2SQLGeneratorHF
from premsql.executors import SQLiteExecutor
# Provide a SQLite file here or see documentation for more customization
dsn_or_db_path = "./data/db/california_schools.sqlite"
agent = SimpleText2SQLAgent(
dsn_or_db_path=dsn_or_db_path,
generator=Text2SQLGeneratorHF(
model_or_name_or_path="premai-io/prem-1B-SQL",
experiment_name="simple_pipeline",
device="cuda:0",
type="test"
),
)
question = "please list the phone numbers of the direct charter-funded schools that are opened after 2000/1/1"
response = agent.query(question)
response["table"]Thats it. It is that simple. The best part of PremSQL is that you can create your pipelines and use them simply like the above using PremSQL. Check out our PremSQL Pipelines documentation for more details.
💡 An i/o standardization for easy customization
One reason for building the PremSQL library is that there are not very well-maintained and well-organized libraries for the same. The reason is that this problem is not the same as other generative AI or LLM-based problems. We have a lot of dependencies with databases at every step. For example, to make a dataset for Text to SQL, you need a module that can connect to databases, fetch the schemas, and apply them to the prompt. Similarly, you must do the same for generators, executors or pipelines. That's why we have introduced a more standard approach to providing inputs, which is used all across PremSQL. If you use it for your private databases, then you can extend and customize it for your data and your use case.
The standardization is simple. Starting with datasets, the raw form of each datapoint must be a JSON blob at least consisting of the following information:
db_id: This is the name of the databasequestion: This is the question asked by the userSQL: The ground truth SQL query.
The keys here are case-sensitive. So here is an example blob of how a single data point should look like:
{
"db_id": "california_schools",
"question": "What is the highest eligible free rate for K-12 students in the schools in Alameda County?",
"SQL": "SELECT `Free Meal Count (K-12)` / `Enrollment (K-12)` FROM frpm WHERE `County Name` = 'Alameda' ORDER BY (CAST(`Free Meal Count (K-12)` AS REAL) / `Enrollment (K-12)`) DESC LIMIT 1",
}
However, please note that you are not constrained to only keep these keys in your dataset. You can put more number of keys like these:
{
"question_id": 0,
"db_id": "california_schools",
"question": "What is the highest eligible free rate for K-12 students in the schools in Alameda County?",
"evidence": "Eligible free rate for K-12 = `Free Meal Count (K-12)` / `Enrollment (K-12)`",
"SQL": "SELECT `Free Meal Count (K-12)` / `Enrollment (K-12)` FROM frpm WHERE `County Name` = 'Alameda' ORDER BY (CAST(`Free Meal Count (K-12)` AS REAL) / `Enrollment (K-12)`) DESC LIMIT 1",
"difficulty": "simple",
"domain": "school and education"
}
So, any key other than db_id, question and SQLWill be automatically used to filter out the datasets. PremSQL automatically identifies which are the filterable keys and lets you filter your dataset based on those keys.
This i/o standardization is maintained not only at the database level but also for generators. PremSQL generators expect the following keys: db_id, question, prompt, db_path. Where db_path is the db connection URI, which lets the generator execute the generated SQL on the database. Once you follow the standardization, you can extend our library to your databases and use cases.
🛣️ Roadmap of PremSQL
As of today, we have successfully rolled out the first release of the PremSQL library. Alongside the release, we continually improve the existing documentation to enhance the overall developer experience.
Synthesizer Component: A significant feature of PremSQL is the synthesizer component, which is designed to generate synthetic datasets from private data. This capability will enable fine-tuning smaller language models, allowing fully private text-to-SQL workflows that safeguard sensitive data.
Agentic Pipelines with Function-Calling Features: Future releases will incorporate advanced agentic methods with new features. These include graph plotting capabilities, natural language analysis, and other enhancements to make the system more versatile and powerful.
Training Better Small Language Models: We actively train our small language models tailored explicitly to PremSQL’s unique requirements. These models will continue to be refined and optimized, ensuring they become increasingly efficient and effective in handling designated tasks.
Optimization of Generators and Executors: We are also trying to optimise existing components, like generators and executors, to enhance their robustness. Planned improvements include parallel processing, significantly speeding up generation and execution times, and making the overall system more efficient.
Last but not least, tests for the stability of the overall library should be included, and a simple UI should be rolled out. Join us in our open-source initiative by putting more issues, providing feedback and contributing by opening pull requests. You can learn more about that in our contributing guidelines.
🌀 Conclusion
Text to SQL and tasks that use the natural language to SQL paradigm can be a huge help for any data analysis task, drive them to scale, and provide autonomy. However, as mentioned earlier, it is not easy to build such a thing fully locally (without the internet), relying on third-party APIs. Sure, our library lets you connect those if needed. However, when databases contain very sensitive data but in huge volumes, it becomes hard to deploy very similar solutions, which could have been done when using closed-source models. Prem's main vision has always been to own your data and models. So does PremSQL. We have just released our first version and are shipping fast for further improvements. In our next release, we will officially release our first Small Language Model for Text to SQL. We would highly appreciate it if you could start the repository and stay tuned for further updates.