Cloud vs Self-Hosted AI: A Practical Guide to Making the Right Choice (2026)
Cloud AI or self-hosted? Compare costs, tradeoffs, and deployment models with real examples. Learn which AI strategy fits your team, workload, and compliance needs.

Enterprise AI spending hit an average of $85,500 per month in 2025, up 36% from the year before. And a growing chunk of that budget goes toward a decision most teams get wrong: choosing between cloud AI services and self-hosted AI models.
The tradeoff sounds simple on paper. Cloud gives you speed. Self-hosting gives you control. But the actual decision depends on your workload volume, regulatory requirements, team size, and how much infrastructure you're willing to manage.
This guide walks through real costs, practical use cases, and a decision framework to help you pick the right approach without overspending or overcommitting.
Cloud AI vs Self-Hosted: What's Actually Different
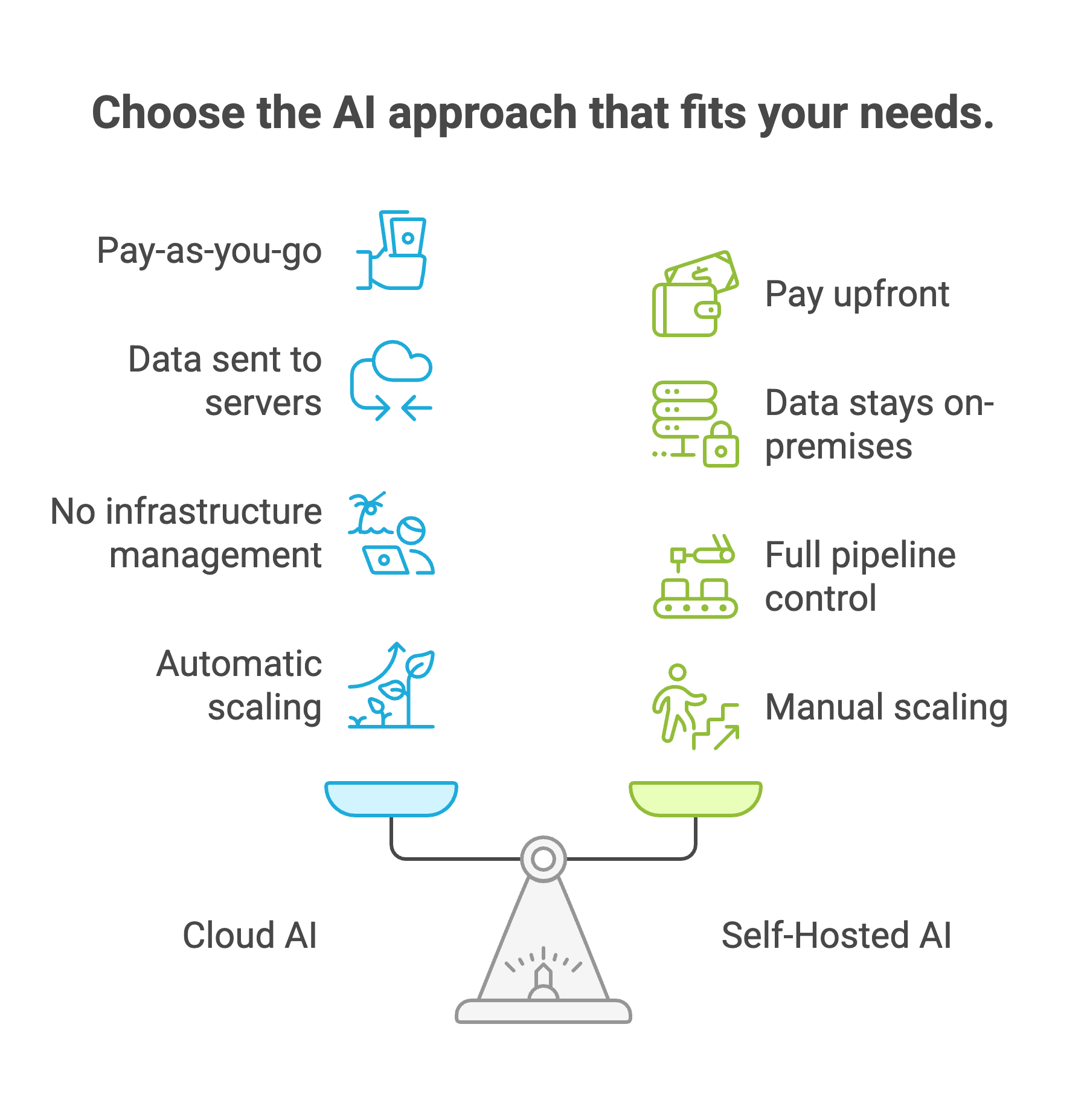
Cloud AI means using APIs from providers like OpenAI, Google, or Anthropic. You send data to their servers, get a response back, and pay per token or per request. No GPUs to provision. No models to maintain. You're renting someone else's infrastructure.
Self-hosted means running models on hardware you control, whether that's on-premises servers, a private cloud, or a VPC you manage. You pick the model, configure it, handle scaling, and own the entire pipeline from input to output.
The core tradeoff comes down to four things: cost structure, data privacy, operational control, and scaling flexibility.
Cloud-based options are pay-as-you-go. Self-hosting is pay-upfront-then-run-free. Neither is universally cheaper. The math depends entirely on your situation and volume.
The Real Cost Comparison: Cloud APIs vs Self-Hosting AI
API pricing looks affordable at small volumes. A single call to GPT-4o costs fractions of a cent. But costs compound fast once you're processing thousands of requests daily.
Here's a rough comparison for a team running 50,000 requests per month (averaging 1,000 input + 1,000 output tokens each):
At 50,000 requests, cloud APIs win on raw cost. At 500,000 requests, self-hosting wins by a wide margin because your GPU cost stays flat regardless of volume. The crossover point for most teams lands somewhere between 100,000 and 300,000 monthly requests.
Fine-tuned smaller models shift this math even further. In one invoice parsing benchmark, a fine-tuned Qwen 7B model outperformed GPT-4o on extraction accuracy while costing roughly 25x less per token. The fine-tuned Qwen 2.5 1B (a fraction of the parameters) matched GPT-4o's performance entirely. At 10M tokens per month, the inference cost difference was $4 on Prem versus $200 on GPT-4o. That's the kind of gap that changes budget conversations.
But hardware isn't the only line item. Running your own models adds operational overhead: MLOps engineers ($150K+ salaries), monitoring tools, security patches, and model updates. A realistic budget for a small self-hosted deployment includes 1-2 FTE engineers dedicated to keeping things running.
For teams that want the economics of self-hosting without building an entire MLOps team, platforms like Prem AI handle the fine-tuning and deployment workflow while keeping data on your infrastructure. Their production deployments show 50% inference time reduction and 70% per-token savings compared to general-purpose cloud APIs. You get cost control without needing to manage the infrastructure from scratch.
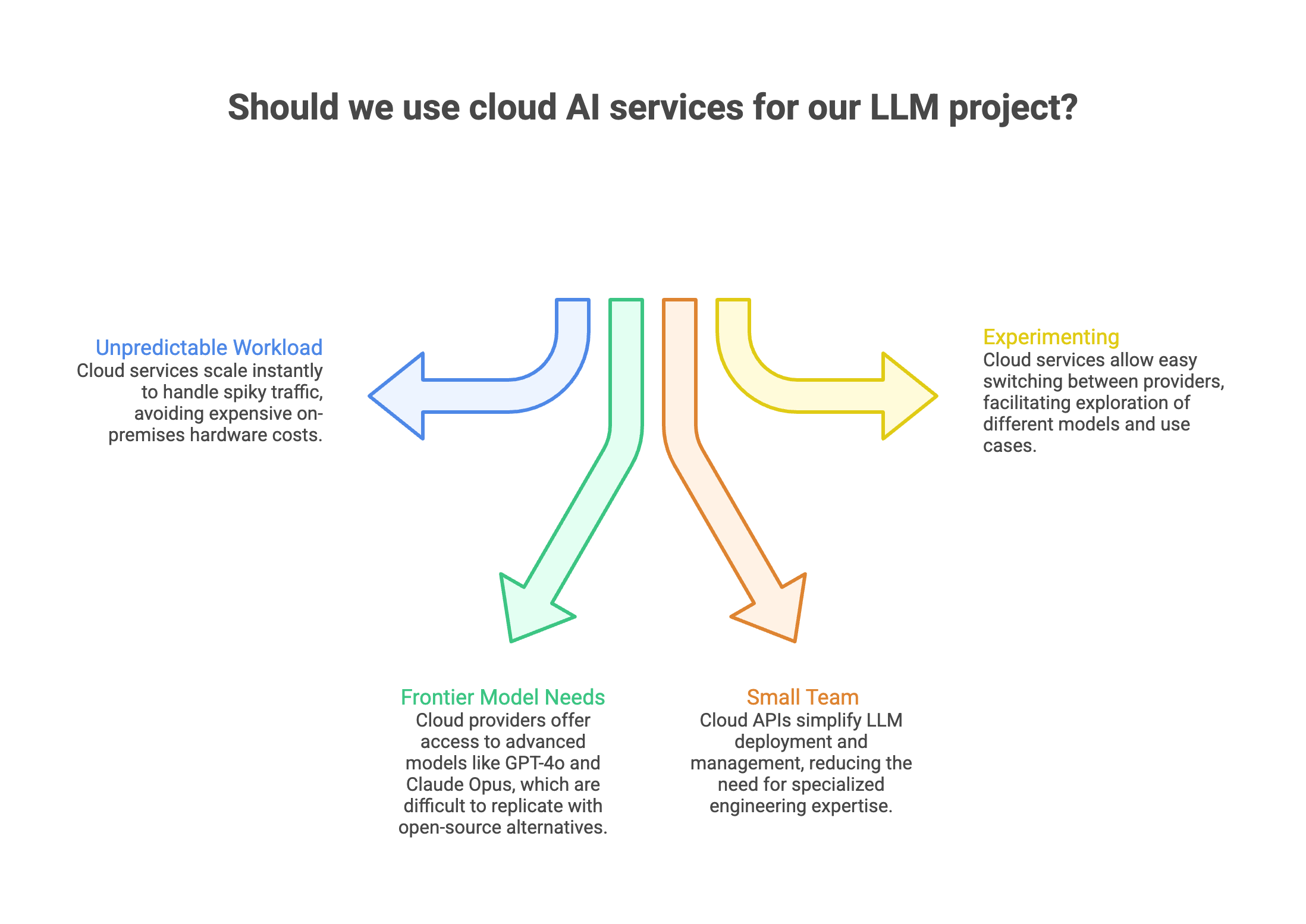
When Cloud AI Services Make Sense
Cloud is the right starting point for most teams.
Skip self-hosting if:
- Your workload is unpredictable. Spiky traffic patterns (holiday surges, product launches, seasonal demand) are expensive to handle with fixed GPU capacity. Cloud-based APIs scale instantly. On-premises hardware doesn't.
- You need frontier model capabilities. GPT-4o, Claude Opus, and Gemini Pro represent billions of dollars in training investment. You can't replicate that with open-source alternatives like Llama or Mistral, especially for complex reasoning, multi-step analysis, or nuanced language tasks.
- Your team is small. If your engineering team doesn't include someone comfortable with GPU provisioning, model serving frameworks like vLLM, and inference optimization, cloud APIs remove that complexity entirely. Most providers offer SDKs that take minutes to integrate.
- You're still experimenting. Early-stage projects change direction constantly. New use cases, different models, shifting requirements. APIs let you swap between providers with a config change, not an infrastructure migration.
When Self-Hosting AI Models Wins
Self-hosting becomes the better choice once specific conditions line up.
1. Compliance demands it.
In regulated industries like finance, healthcare, and government, data residency isn't optional. GDPR, HIPAA, and SOC 2 all impose restrictions on where data can be processed. Cloud APIs send your data to third-party servers. Self-hosted models keep it on your network, which simplifies compliance audits significantly. For teams operating under strict data privacy rules, building on a private AI platform eliminates a whole category of risk.
This isn't theoretical. Over 15 European banks currently use Prem AI to run compliance automation agents powered by small language models. These institutions can't risk sending proprietary financial data to external servers. They need absolute data sovereignty, full audit trails, and models that run entirely within their own infrastructure. Grand Compliance, a Nordic RegTech company backed by 400+ GRC experts at Advisense, integrated Prem's fine-tuning into their workflow serving roughly 700 financial institutions. Their CEO noted that the fine-tuning capability allowed them to tailor models to the specific needs of the financial sector, making regulatory adherence more precise and efficient.
2. You need custom models.
Cloud APIs give you general-purpose capabilities. But if your use case requires domain-specific knowledge (medical terminology, legal clauses, financial instruments), fine-tuning your own model delivers better accuracy at lower cost than prompting a generic one.
This is where the self-hosted advantage gets practical. Fine-tuning Llama, Mistral, or Qwen on your proprietary data, then deploying them to your own infrastructure, creates something that actually understands your business. Platforms like Prem Studio make this accessible without requiring a dedicated ML engineering team, supporting 30+ base models with built-in evaluation.
3. Volume is high and predictable.
Once you're processing hundreds of thousands of requests with consistent patterns, on-premise costs flatten while API costs scale linearly. Organizations running large-scale production workloads often see 30-50% savings after switching to custom models optimized for their specific tasks.
4. You want smaller, faster models.
Data distillation and fine-tuning let you create compact models that match or beat larger cloud models on narrow tasks. A 7B parameter model fine-tuned on your data can outperform a 70B general-purpose model for your specific use case, while running on cheaper hardware with lower latency.
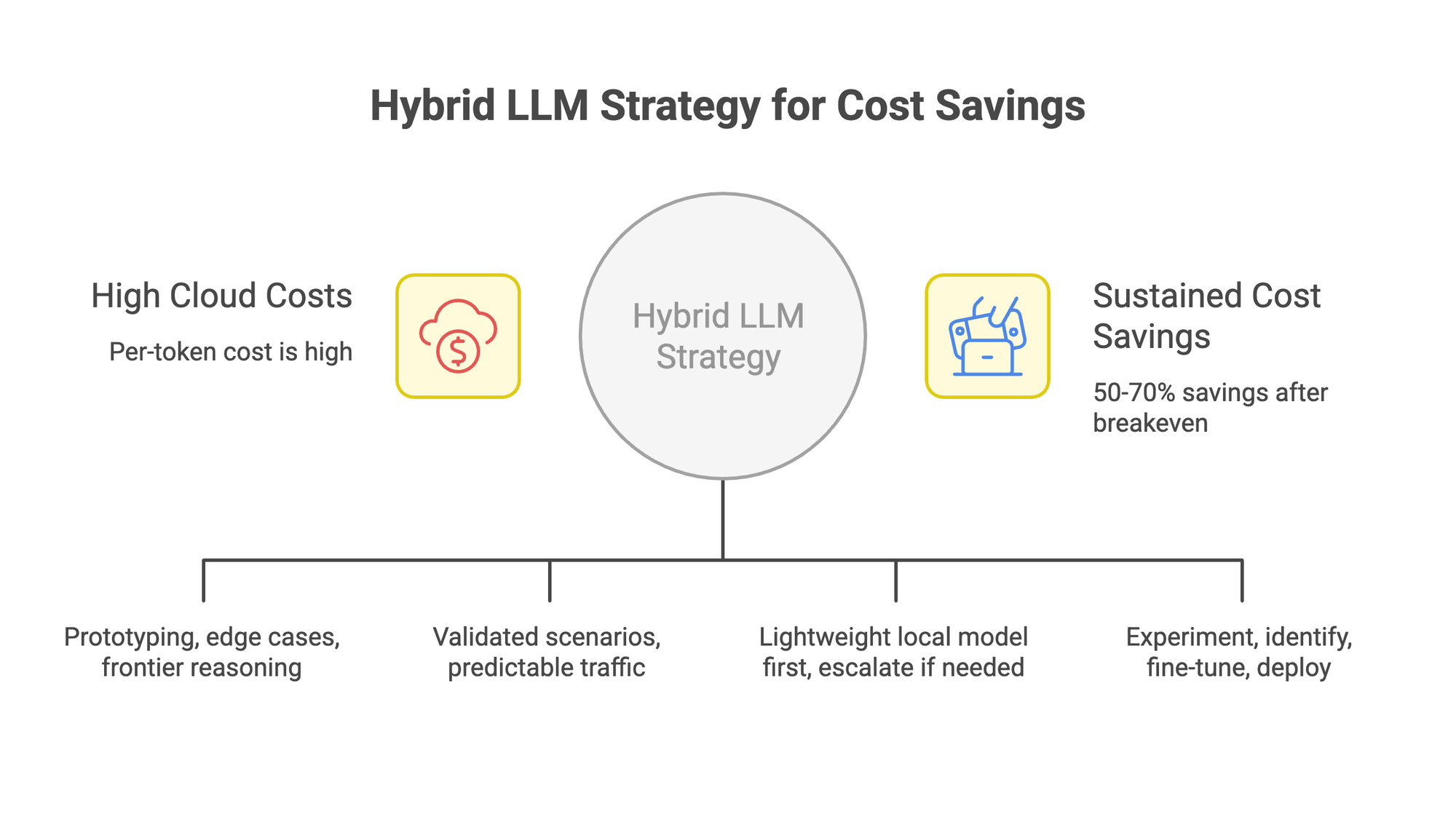
The Hybrid Approach Most Teams Actually Use
Most organizations don't pick one side. They combine cloud and self-hosted components based on the task.
A typical hybrid strategy looks like this:
Cloud for exploration and edge cases. Use OpenAI or Anthropic APIs when you're prototyping new features, handling rare complex queries, or need frontier reasoning capabilities. These are low-volume, high-value interactions where the per-token cost is justified.
Self-hosted for production workloads. Once a scenario is validated and the traffic pattern is predictable, move it to your own model. Document classification, customer support triage, content moderation, data extraction, and regulatory checks are all strong candidates. Companies processing 500M+ tokens monthly on Prem's on-premise deployment typically reach breakeven in 12-18 months, with 50-70% sustained savings after that.
Cascading architecture for cost control. Route requests to a lightweight local model first. If the confidence score is low, escalate to a cloud-based frontier model. This approach cuts costs on the 80% of requests that don't need premium capabilities, while still handling the hard 20%.
The enterprise fine-tuning workflow fits naturally into this pattern. You experiment with cloud APIs, identify which tasks benefit from customization, then fine-tune and deploy your own model for production. The automation around dataset preparation and evaluation makes this cycle repeatable without heavy engineering lift.
A Decision Framework for Cloud vs Self-Hosted AI
Use this table to map your situation to the right model:
If you land in the hybrid column for most rows, that's normal. Most enterprise deployments end up combining cloud and self-hosted components within the same product.
Frequently Asked Questions
Is running your own AI models always cheaper than cloud?
No. Hosting locally is cheaper only at high, predictable volumes. Below roughly 100K requests per month, APIs typically cost less when you factor in GPU leases, ops overhead, and engineering time. The break-even depends on your specific model size, hardware choice, and utilization rate.
Can I self-host models like Llama or Mistral for commercial use?
Yes. Most popular open-source models (Llama 3.x, Mistral, Qwen) allow commercial use under their licenses. Check the specific license terms, but running these for internal or customer-facing applications is standard practice. Tools like vLLM, Ollama, and Prem AI's self-hosted LLM guide make the setup straightforward.
What compliance advantages does running self-hosted models offer?
When you self-host, data never leaves your controlled environment. This makes it easier to satisfy data residency requirements under GDPR, maintain audit trails for SOC 2, and ensure PHI stays protected under HIPAA. Cloud providers are improving their compliance offerings, but self-hosting gives you complete control over where data flows.
Do I need a large engineering team to self-host?
It depends on your approach. Running raw open-source models on bare metal requires significant MLOps expertise. But managed platforms reduce that burden. Prem AI, for example, handles fine-tuning, evaluation, and rollout while keeping everything on your infrastructure. One enterprise user on AWS Marketplace reported that Prem Studio's evaluation and fine-tuning workflow reduced their time-to-market by roughly 10x compared to building the pipeline in-house. You still need someone who understands the workflows, but you don't need a 10-person ML team.
What's the best way to start evaluating your options?
Start with cloud APIs. Build your application, measure request volumes, and identify which tasks need customization. Once you have stable, high-volume workloads, evaluate the cost of hosting those specific tasks yourself. Keep APIs for everything else. This phased approach avoids premature infrastructure investment while setting you up for long-term cost efficiency.
Making the Right Choice
The decision between cloud and self-hosted isn't permanent. Most teams start with APIs, identify high-volume or regulation-sensitive workloads, and gradually move those to their own infrastructure.
The key is matching each workload to the right deployment model rather than forcing everything into one bucket. Cloud for flexibility and frontier capabilities. Self-hosted for cost control, privacy, and customization.
A hybrid of both for production systems that need to balance all three.
If your team is evaluating on-premise options and needs a path from dataset to production model without building an MLOps team from scratch, explore Prem AI's enterprise platform or start with the documentation. Over 10M documents have been processed through the platform with zero data leaks, across 15+ enterprise clients running 30+ trained models in production.